
In todays information driven world having access to data is crucial. Data scientists, marketers and SEO experts greatly benefit from the ability to extract and analyze information obtained from Google search outcomes. Scrutinizing Google search results offers insights into patterns, competitor evaluations, keyword effectiveness and more.
Nevertheless, navigating this process of how to scrape google search results, it comes with challenges. Both technical and legal in nature. This article aims to assist you in navigating the complexities of collecting Google search outcomes using Python while addressing aspects such, as legality concerns, technical obstacles and a practical application utilizing a generic API.
What is a Google SERP?
When someone searches on Google they see a bunch of stuff, on the results page. Like search results, ads, featured snippets, knowledge panels, images and videos. It’s important to know how this page is set up if you want to scrape or find information easily.
Components of a Google SERP
Organic Search Results: Here are the primary search outcomes that Google prioritizes according to its system. They typically consist of a heading, web address and a brief excerpt of content.
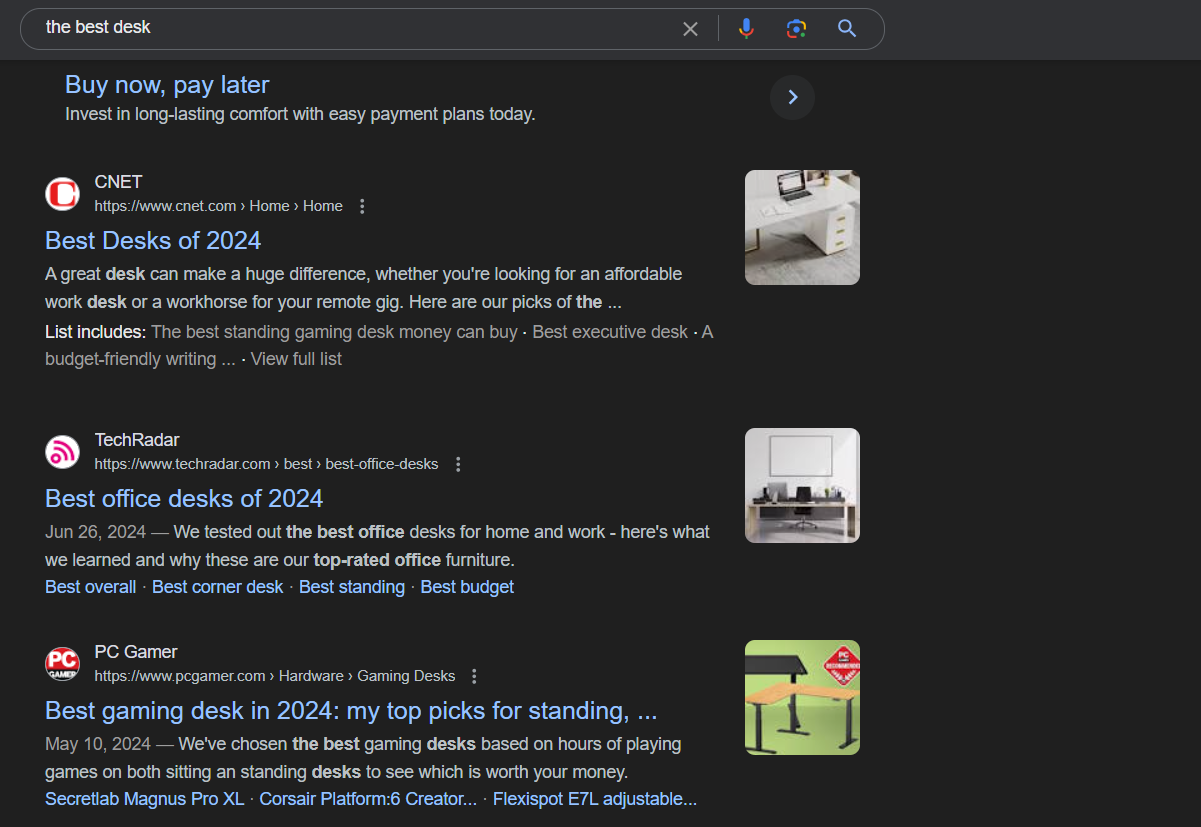
Paid Advertisements: Google advertisements can be seen at both the beginning and end of the search engine results page (SERP). They are identified by a small “Ad” label.
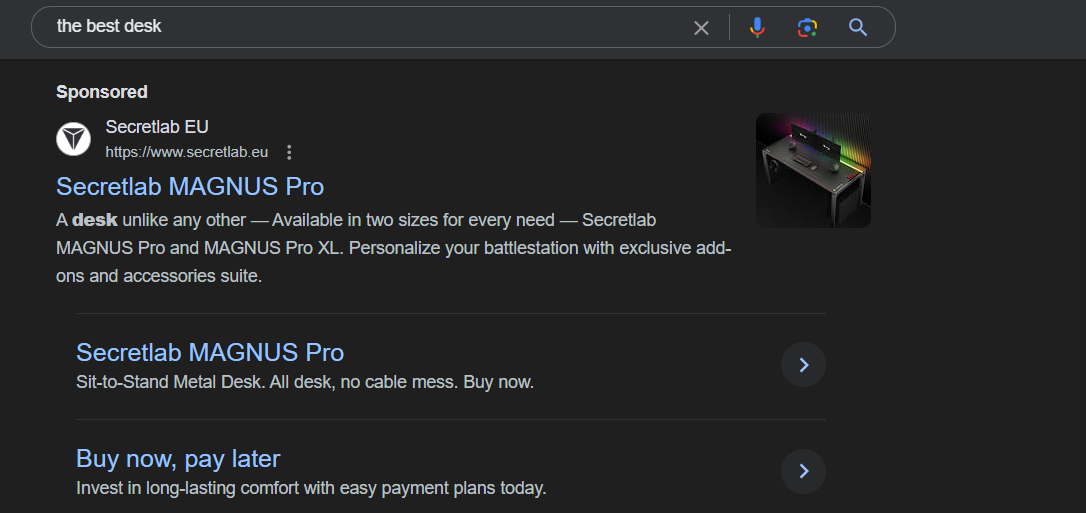
Featured Snippets: At times you may come across boxes at the top of search results that offer a response, to your query.
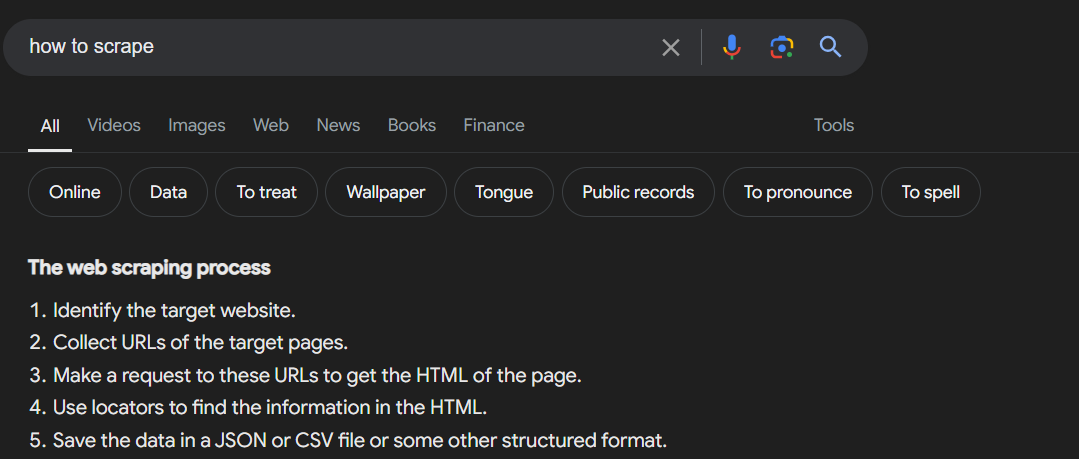
Knowledge Panels: The information boxes are located on the side of the search engine results page (SERP) and offer in depth details, about individuals, locations and objects.
Image and Video Carousels: It shows pictures and videos that are connected to the search term.
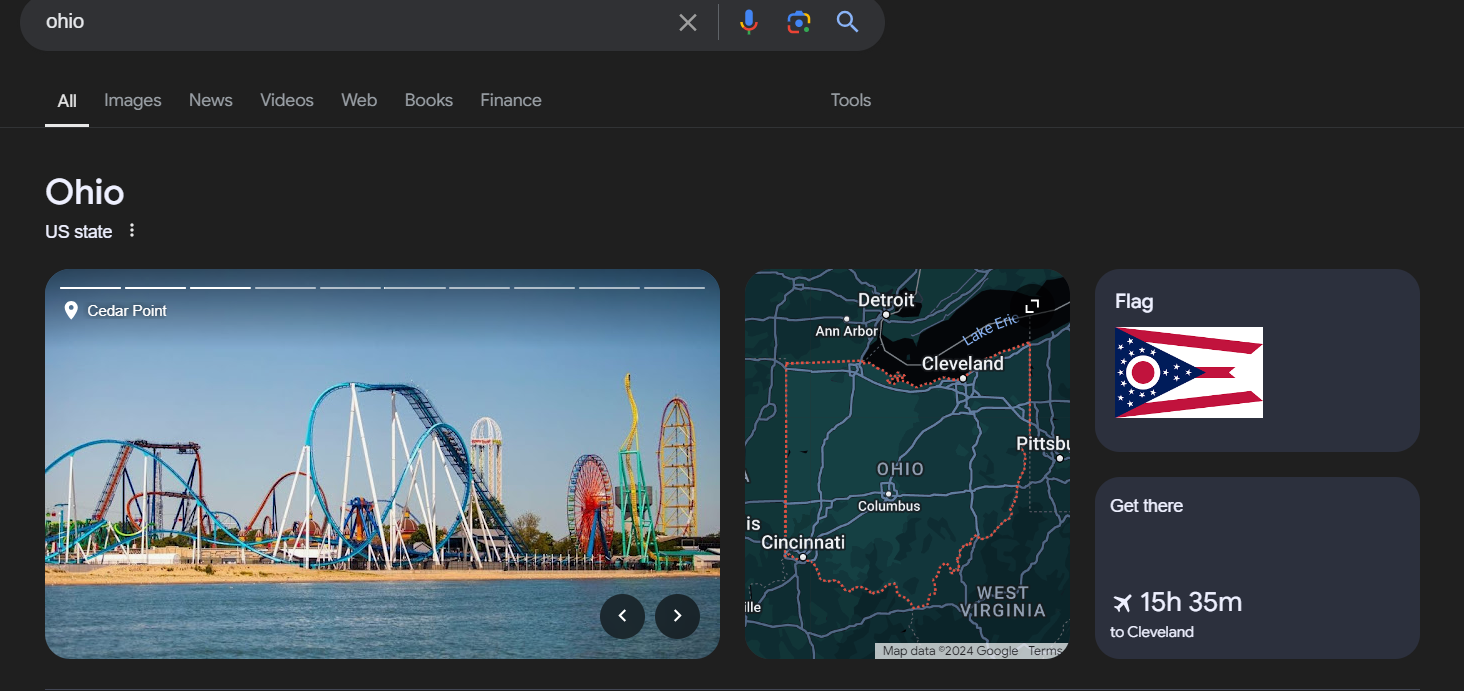
Local Pack: When you search for places on Google it displays a map featuring businesses along, with their contact details.
Every part comes with its distinct arrangement and needs specific approaches, for retrieval making the scraping procedure more intricate.
Is it Legal to Scrape Google Search Results?
The legality of extracting information from Google search results is unclear. Although collecting data that’s publicly available is usually allowed Googles terms of service specifically forbid automated retrieval of their search results. Therefore scraping Google search results without obtaining consent from Google may result in legal repercussions such, as IP bans and potential legal proceedings.
Legal Considerations
Terms of Service: Google clearly mentions in its terms of service that unauthorized automated access, to their services is not allowed.
Robots.txt: Googles robots.txt file specifies the areas, on their website that web crawlers are not allowed to access. Disregarding this file could result in complications.
Data Privacy Laws: In some places and depending on the information you’re gathering there could be privacy regulations like GDPR, in the EU that you should take into account.
Ethical Considerations
Respect for Services: Adhering to Googles terms of use is essential for upholding practices, in web scraping.
Impact on Servers: Automated web scraping can place a burden on servers, which could impact the overall performance of the service, for other users.
Scrape Google Search Results: The Difficulties
Automated web scraping can place a burden on servers, which might impact the services performance for other users. Extracting data, from Google search results can pose challenges and complexities.
Technical Challenges
Dynamic Content: Google often makes changes to how search results appear and uses JavaScript to load content in a way. This can pose a challenge, for scraping data using HTML parsers.
CAPTCHA and Rate Limiting: Google uses tools such, as CAPTCHA and rate limiting to stop automated scraping. When you come across a CAPTCHA it can pause your scraping activities.
IP Blocking: Repeated inquiries coming from the IP address may result in the blocking of the IP causing interruptions, to the data scraping procedure.
Changing HTML Structure: Google often updates the layout of its HTML, which can pose a challenge when trying to keep a scraping script.
Overcoming Technical Challenges
Using Headless Browsers: Tools such, as Selenium have the capability to display JavaScript and manage content.
Proxies and VPNs: Utilizing a group of proxies or a VPN can assist in spreading out requests and preventing IP blockages.
Handling CAPTCHAs: Websites such, as 2Captcha have the ability to automatically solve CAPTCHAs.
Monitoring Changes: Make sure to adjust your web scraping program to accommodate any modifications, in Googles HTML layout.
Scraping Public Google Search Results with Python Using API
Even though it can be tough you can scrape Google search results using Python successfully if you have the strategy and tools. Here we offer a walkthrough using a common API to demonstrate how its done.
Step 1: Setting Up the Environment
Make sure you have Python set up on your computer. You’ll also have to install the required libraries:
pip install requests beautifulsoup4
These tools can assist you in sending HTTP requests and extracting information, from HTML documents.
Step 2: Understanding the API
In this scenario lets consider a made up API that allows users to access search outcomes, from Google. The API is designed to manage the intricacies of engaging with Google like overcoming CAPTCHAs and controlling usage limits.
Step 3: Making API Requests
Here is an example Python script that you can use to send requests, to the API and extract information from Google search results.
import requests
from bs4 import BeautifulSoup
# Replace with your API endpoint
API_ENDPOINT = "https://api.example.com/google-search"
# Define your search parameters
params = {
'query': 'web scraping with Python',
'location': 'United States',
'language': 'en',
'num_results': 10
}
# Make the request to the API
response = requests.get(API_ENDPOINT, params=params)
data = response.json()
# Parse the results
for result in data['results']:
title = result['title']
link = result['link']
snippet = result['snippet']
print(f"Title: {title}\nLink: {link}\nSnippet: {snippet}\n")
In this code we send a GET request to the API using search criteria. The API responds with the search outcomes, in JSON form, which we then analyze and display.
Step 4: Handling Dynamic Content
When the search results include elements you might have to utilize a headless browser such as Selenium, for handling JavaScript. Here is a sample;
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
# Set up the Selenium WebDriver
driver = webdriver.Chrome()
# Perform the Google search
driver.get('https://www.google.com')
search_box = driver.find_element_by_name('q')
search_box.send_keys('web scraping with Python')
search_box.send_keys(Keys.RETURN)
# Extract the search results
soup = BeautifulSoup(driver.page_source, 'html.parser')
results = soup.find_all('div', class_='g')
for result in results:
title = result.find('h3').text
link = result.find('a')['href']
snippet = result.find('span', class_='aCOpRe').text
print(f"Title: {title}\nLink: {link}\nSnippet: {snippet}\n")
# Close the browser
driver.quit()
This code utilizes Selenium for executing a search, on Google and BeautifulSoup for parsing the search outcomes.
Step 5: Respecting Google’s Terms of Service
When you’re gathering information, from Google search outcomes it’s crucial to adhere to Googles terms of service. Make sure to use the API steer clear of sending an excessive number of requests within a brief timeframe and think about utilizing proxies to spread out your inquiries.
Advanced Techniques for Scraping Google Search Results
Rotating Proxies: To prevent getting blocked by IP filters consider using a variety of rotating proxies. Platforms such, as ProxyMesh and ScraperAPI offer rotating proxy services.
User Agents: Vary the user agents randomly to simulate web browsers and prevent detection.
Headless Browsers: Advanced scraping tasks can be tackled using tools such, as Puppeteer and Playwright especially when dealing with JavaScript rendered pages.
Handling Pagination: When you need to gather data from search result pages you can manage the pagination by either clicking on the “Next” button or modifying the starting parameter in your search query.
Conclusion
Using Python to scrape Google search results can provide insights and support competitive analysis. However this approach presents obstacles and legal implications. By utilizing an API and following recommended guidelines you can efficiently retrieve meaningful information, from Googles search engine results pages (SERPs). It is essential to uphold Googles terms of service at all times and handle the extracted data responsibly.
This detailed manual offers experienced users the insights and resources necessary to extract Google search results ethically. By employing the methods you can access a trove of valuable data to inform decision making processes and strategic planning. Enjoy your scraping endeavors!
Take your data scraping to the next level with IPWAY’s datacenter proxies!