
In the evolving world of e commerce Amazon shines as a vast treasure trove of essential information vital for studying market patterns exploring rival businesses and conducting thorough Amazon price check.
As we enter the year 2024 keeping track of Amazon for pricing details past records and item specifications has grown crucial yet complex, for data professionals and tech experts alike. This manual seeks to shed light on the art of gathering data from Amazon guaranteeing that your web scraping endeavors adhere to standards and comply with legal regulations.
Web scraping is about collecting information from websites. Amazon, known for its range of products and flexible pricing is a popular choice for this technique. This tutorial will guide you on creating the setup for scraping Amazon covering everything from managing API access, to getting prices of top selling items and storing your results.
1.Prepare the Enviroment for Amazon Price Check
Before you start your web scraping adventure it’s important to establish a development environment. Python is widely used for web scraping due to its user nature and the wide range of useful libraries it offers. Make sure you have the up to date version of Python installed and choose a code editor, like Visual Studio Code or PyCharm to help with writing and debugging your code.
2.Install Dependencies
The core of Amazon scraping involves using Python libraries that make the process easier. BeautifulSoup and Requests are crucial, for interpreting HTML and handling HTTP requests respectively. Moreover boosting performance can be achieved by incorporating lxml as a parser. Execute the following command in your terminal to install these libraries:
pip install beautifulsoup4 requests lxml
3.Import Libraries
With the dependencies in place, the next step is to import them into your Python script. This enables the functionality needed to request and parse web content:
import requests
from bs4 import BeautifulSoup
4.Mastering the Use of Headers for Scraping
In this guide we delve into the methods of retrieving information from Amazon without tapping into its API. A crucial element of data extraction includes the strategic deployment of headers. Following Amazons robots.txt rules is merely the step. To scrape data effectively without encountering access restrictions emulating a browser via your request headers is essential.
This strategy plays a role, in smoothly navigating Amazons website layout enabling you to gather information efficiently while upholding the platforms scraping guidelines:
# Define the headers to mimic a browser request
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
5.Navigating Through Proxy Variables for Efficient Scraping
When you’re pulling information from Amazon using proxy variables can really help to make the scraping process smoother. To start off you need to set up the proxy settings that will let you tap into Amazons data without raising any alarms. With the requests library tweak your scraping script to go through these variables hiding your real IP address and making it seem like you’re accessing the site from different places.
This approach not makes sure that you can fetch web content seamlessly but also helps you avoid potential blocks by looking like a regular user from various locations. By getting the hang of using variables you can keep your scraping activities legit and maintain uninterrupted access, to Amazons treasure trove of data resources.
proxyUrl = 'europe.ipway.pro'
proxy_user = 'ipway_user_name'
proxy_pass = 'password'
proxy_port = 'port'
proxies = {
"http": f"http://{proxy_user}:{proxy_pass}@{proxyUrl}:{proxy_port}/",
"https": f"http://{proxy_user}:{proxy_pass}@{proxyUrl}:{proxy_port}/"
}
6.Navigating Through Proxy Variables for Efficient Scraping
Amazons top selling lists provide information on what consumers prefer and the current market trends. Begin by locating the web address of the selling page, for your chosen category. Use the requests library to fetch the page content, then parse the HTML with BeautifulSoup to extract product names and their corresponding prices:
# Function to scrape best-seller books' prices and titles
def scrape_amazon_best_sellers(url,proxies):
# Send a HTTP request to the URL
response = requests.get(url, headers=headers, proxies=proxies, stream=True)
# Parse the content of the response using BeautifulSoup
soup = BeautifulSoup(response.content, 'lxml')
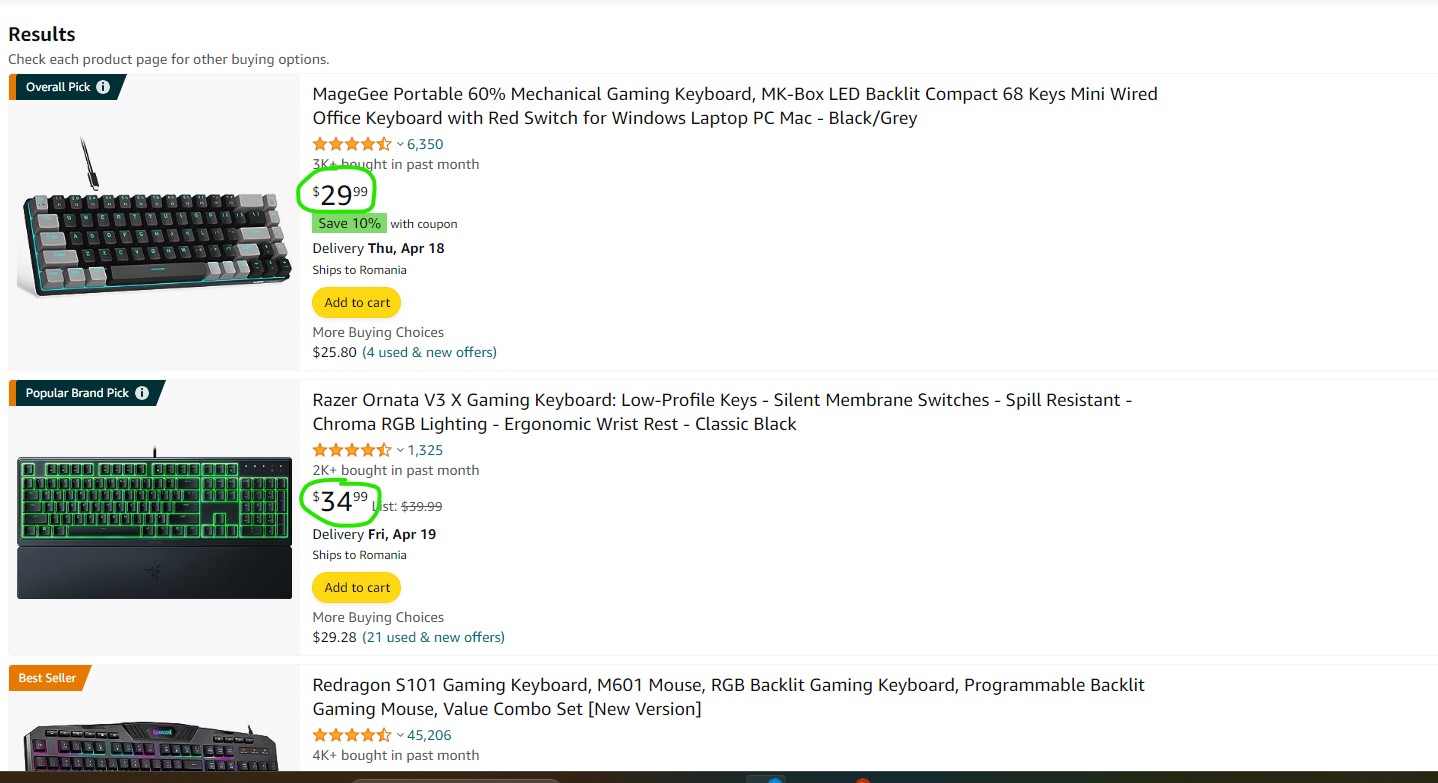
7.Getting Best-Seller Titles & Prices
To get the prices from Amazon search outcomes create the search link for the product or category you’re interested in. Just, like before use requests and BeautifulSoup to analyze the webpage. Iterating through the search results, extract the necessary details such as product name, price, and rating:
# Find all the div elements that contain each product
for div in soup.find_all("div", attrs={"id": "gridItemRoot"}):
# Extract title
title =''
title_container = div.find("div", attrs={"class": "p13n-sc-uncoverable-faceout"})
if title_container is not None:
title = div.find_all("img", attrs={"class": "a-dynamic-image p13n-sc-dynamic-image p13n-product-image"})[0].get('alt')
else:
title = "No title available"
# Extract price
price = ''
price_holder = div.find_all("div", attrs={"class": "a-row"})[3]
if price_holder is not None:
price_container = price_holder.find("span", attrs={"class": "_cDEzb_p13n-sc-price_3mJ9Z"})
if price_container is None:
price_container = price_holder.find("span", attrs={"class": "p13n-sc-price"})
price = price_container.get_text()
else:
price = "No price available"
# Append the extracted data to the products list
products.append({"title": title, "price": price})
# URL of the Amazon Best Sellers page for Books
url = 'https://www.amazon.com/best-sellers-books-Amazon/zgbs/books/'
# Scrape the data
products = scrape_amazon_best_sellers(url,proxies)
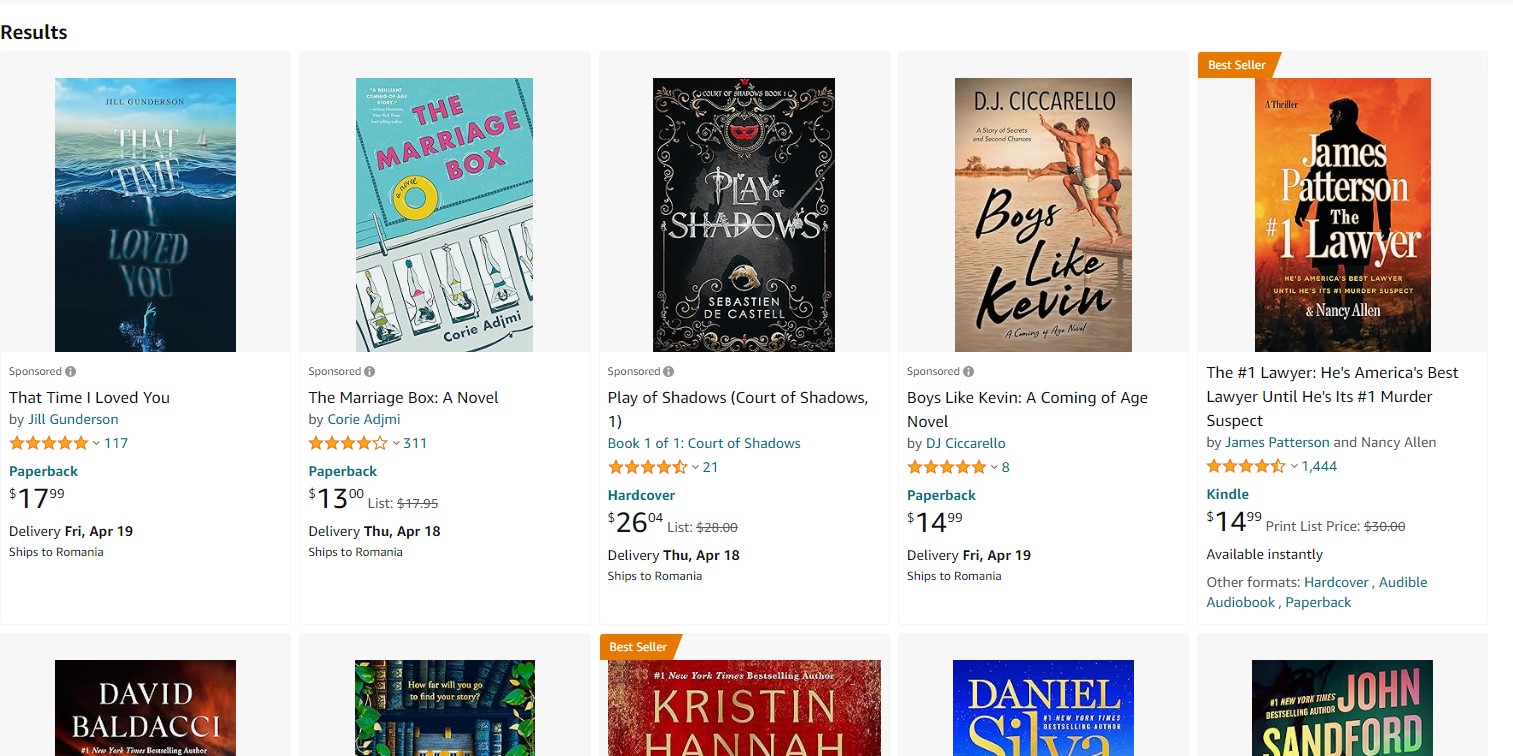
8.Write the scraped data to a CSV file
By using the methods, in best selling books and online search results you can gather price information from different Amazon categories. Tailor your data extraction approach according to the layout of each categories page to retrieve the necessary details.
9.Save to a CSV File
When it comes to managing and safeguarding the abundance of data gathered from Amazon saving the extracted information to a CSV file emerges as an effective strategy. This technique not aids in simpler analysis but also streamlines the sharing of discoveries with colleagues or incorporating them into different programs. Pythons integrated csv module offers a route, for converting your accumulated data into an organized CSV layout.
Before you start make sure your scraping script is ready to gather the data you need in a way that can easily be converted to CSV. Then use Pythons module to begin writing. Here’s a thorough explanation of the steps you’ll be taking:
# Write the scraped data to a CSV file
with open('amazon_best_sellers.csv', 'w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerow(["Title", "Price"]) # Write the header row
for product in products:
writer.writerow([product['title'], product['price']]) # Write product data
10.The Complete Code
By following the steps mentioned earlier you can put together a script designed for extracting information, from Amazon. This script should cover everything starting from configuring your system and installing components to retrieving data and storing it in a usable form.
Here is a Python script that details the procedure starting with configuring headers to imitate a web browser retrieving information from Amazons top selling page analyzing the HTML to retrieve product names and prices and ultimately saving the collected data into a CSV file. This demonstration focuses on the ‘Books section, for scraping. Can be adjusted for different categories or search outcomes.
pip install beautifulsoup4 requests lxml
import requests
from bs4 import BeautifulSoup
# Define the headers to mimic a browser request
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
proxyUrl = 'europe.ipway.pro'
proxy_user = 'ipway_user_name'
proxy_pass = 'password'
proxy_port = 'port'
proxies = {
"http": f"http://{proxy_user}:{proxy_pass}@{proxyUrl}:{proxy_port}/",
"https": f"http://{proxy_user}:{proxy_pass}@{proxyUrl}:{proxy_port}/"
}
# Function to scrape best-seller books' prices and titles
def scrape_amazon_best_sellers(url,proxies):
# Send a HTTP request to the URL
response = requests.get(url, headers=headers, proxies=proxies, stream=True)
# Parse the content of the response using BeautifulSoup
soup = BeautifulSoup(response.content, 'lxml')
###6.end
# Initialize a list to store the scraped data
products = []
# Find all the div elements that contain each product
for div in soup.find_all("div", attrs={"id": "gridItemRoot"}):
# Extract title
title =''
title_container = div.find("div", attrs={"class": "p13n-sc-uncoverable-faceout"})
if title_container is not None:
title = div.find_all("img", attrs={"class": "a-dynamic-image p13n-sc-dynamic-image p13n-product-image"})[0].get('alt')
else:
title = "No title available"
# Extract price
price = ''
price_holder = div.find_all("div", attrs={"class": "a-row"})[3]
if price_holder is not None:
price_container = price_holder.find("span", attrs={"class": "_cDEzb_p13n-sc-price_3mJ9Z"})
if price_container is None:
price_container = price_holder.find("span", attrs={"class": "p13n-sc-price"})
price = price_container.get_text()
else:
price = "No price available"
# Append the extracted data to the products list
products.append({"title": title, "price": price})
return products
# URL of the Amazon Best Sellers page for Books
url = 'https://www.amazon.com/best-sellers-books-Amazon/zgbs/books/'
# Scrape the data
products = scrape_amazon_best_sellers(url,proxies)
# Write the scraped data to a CSV file
with open('amazon_best_sellers.csv', 'w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerow(["Title", "Price"]) # Write the header row
for product in products:
writer.writerow([product['title'], product['price']]) # Write product data
Conclusion
Wrapping up this guide on becoming proficient in web scraping Amazon it’s evident that being able to conduct an Amazon price check and utilize an Amazon price checker efficiently is highly important. In the competitive world of online shopping keeping yourself updated on price variations and product specifics on Amazon can provide you with a notable advantage.
Whether you’re a data specialist looking to assess market shifts or a software developer designing solutions for automated price monitoring, the expertise and insights you’ve gained here will definitely push you closer to achieving success.
Don’t forget, when you scrape data from Amazon it’s not about gathering information, it’s also about using that data to help you make smart choices. By incorporating Amazon price checking methods into your routine, you gain the ability to discover fresh perspectives and possibilities. This manual has equipped you with the skills and strategies required to effectively maneuver through the intricacies of web scraping.
Embrace the opportunities presented by Amazon data with the advice given you are ready to start your web scraping projects keeping yourself competitive in the world of retail. Enjoy scraping and may your investigations into Amazon prices uncover insights and competitive edges.
Explore IPWAY for proxy solutions tailored for companies. Start with a free trial!