
Data pipeline architectures serve as the foundation for any data driven business application. They determine how data is collected, processed and delivered from sources to different destinations like databases, dashboards or reports. These architectures play a role in enabling businesses to efficiently access, analyze and leverage data.
In this article we will explore the concept of data pipeline architecture its significance in business operations delve into data pipelines discuss the process of designing a data pipeline provide some common examples of data pipelines and highlight the distinctions, between data pipelines and ETL pipelines.
What is data pipeline architecture?
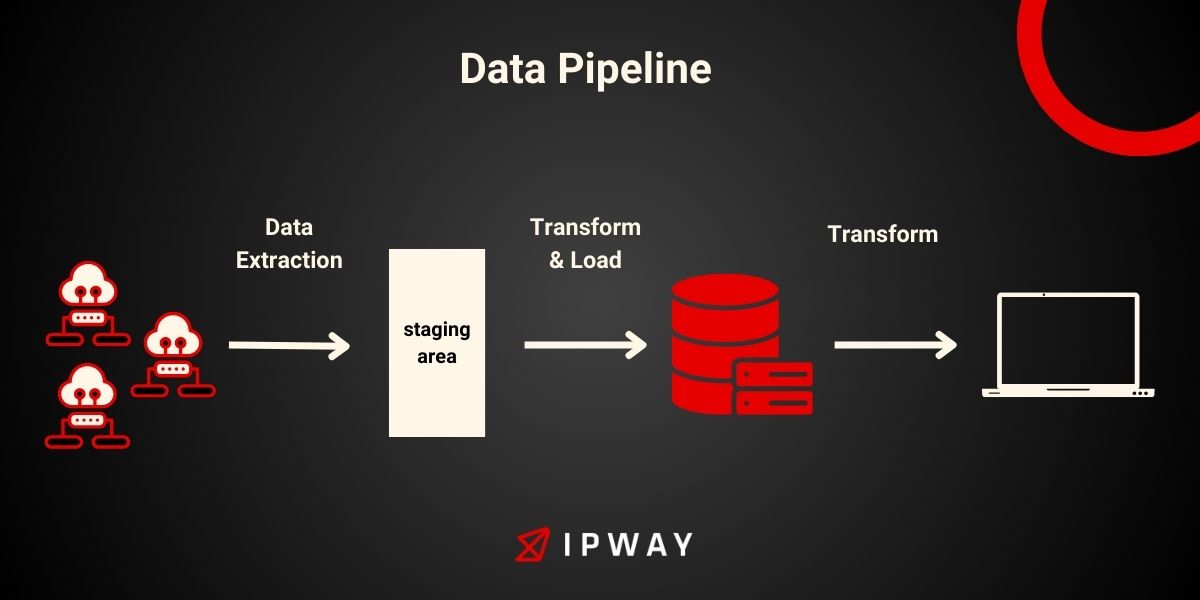
Data pipeline architecture refers to a collection of components, processes and guidelines that dictate the movement of data from one location, to another. In essence it comprises four elements:
- Data sources refers to the origins of data which can include web pages, applications, sensors or files. These sources can be categorized as structured, semi structured or unstructured. They come in various formats, like JSON, XML, CSV or PDF.
- Data ingestion refers to the process of gathering, importing and verifying data from sources. The method of data ingestion can vary based on factors such as the frequency, volume and speed at which the data is received. Additionally data ingestion may include activities, like data cleansing transforming and enriching to ensure that the data is of quality and remains consistent throughout.
- Data processing refers to the application of logic, algorithms and functions to data in order to uncover insights, patterns and trends. This process can be carried out using a range of tools and frameworks like Spark, Hadoop or Kafka. It involves tasks such, as data analysis, data mining, data modeling and data visualization.
- Data delivery refers to the procedure of moving, storing and showcasing data to designated destinations like databases, dashboards or reports. Various protocols and formats like FTP, HTTP or SMTP are employed for data delivery, which may also involve measures such, as data compression, encryption and authentication to guarantee the security and privacy of the transmitted information.
Why is data pipeline architecture important?
Data pipeline architecture is important because it enables businesses to:
- Leverage data : Data pipeline architecture plays a role in enabling businesses to utilize data effectively. By implementing a designed data pipeline architecture businesses can leverage data as a valuable strategic asset. This architecture ensures that data is easily accessible readily available and actionable empowering businesses to gain insights make decisions and create substantial value from their data resources.
- Improve performance : Data pipeline architecture enables businesses to enhance performance by ensuring data is efficient, dependable and scalable. Implementing data pipeline architecture assists businesses in reducing delays increasing data processing speed and effectively managing volumes of data.
- Enhancing quality : The architecture of a data pipeline enables businesses to enhance the quality of their data by ensuring accuracy, consistency and compliance. Implementing data pipeline architecture assists businesses in eliminating errors resolving conflicts and adhering to data standards and regulations.
Designing a data pipeline
Designing a data pipeline encompasses the task of outlining the criteria, specifications and elements of a data pipeline structure that aligns with the business requirements and objectives. The process involves steps to ensure an effective data pipeline is created:
- Identify data sources and destinations : The initial task is to determine the origins and targets of the data. These can include sources like web pages, applications, sensors or files as well as different destinations like databases, dashboards or reports. It’s also important to identify the data formats such as JSON, XML, CSV or PDF and the protocols used for transferring the data, like FTP, HTTP or SMTP.
- Define data ingestion strategy : To establish a plan for bringing in data the next stage involves determining the approach for data ingestion. This entails deciding whether to use batch processing, streaming or a combination of both depending on factors like how the data is generated, how much of it there is and how quickly it needs to be processed. Additionally it includes selecting tools and frameworks like Flume or NiFi for data ingestion purposes.
- Define data processing strategy : The next stage involves determining the approach for handling data taking into account the logic, algorithms and functions that will be applied to it. It also includes specifying the tools and frameworks used for processing data, such as Spark, Hadoop or Kafka. Additionally the processes involved in data processing, like data analysis, data mining, data modeling or data visualization need to be defined.
- Define data delivery strategy : The next step is to determine how data will be delivered, taking into account factors like transfer, storage and presentation. This stage also entails selecting the tools and frameworks for data delivery, such, as Hive, HBase or Cassandra. Additionally it involves implementing processes like data compression, encryption and authentication to ensure efficient delivery of data.
- Test and monitor data pipeline : Step number five involves the task of testing and closely monitoring the data pipeline. This ensures that it functions smoothly performs well and maintains quality. To achieve this we need to test the data pipeline for any errors, exceptions or potential failures. Simultaneously we must keep an eye on its latency, throughput and overall load using a range of tools and metrics, like Airflow, Oozie or Nagios.
Common examples of data pipelines
There are different types of data pipeline architectures, which vary depending on how data is ingested, processed and delivered. Here are a few seen examples of data pipelines :
- Streaming pipeline : A streaming pipeline refers to an architecture used for handling data that is continuously generated and requires time or near real time processing and delivery. It utilizes streaming tools and frameworks like Kafka, Spark Streaming or Storm. This type of pipeline is best suited for generated data such as sensor data, social media posts or web log data. It ensures latency and high throughput, for efficient data handling.
- Lambda architecture : A lambda architecture represents a type of data pipeline structure that combines the use of batch and streaming pipelines. It leverages tools and frameworks like Hadoop, Spark or Kafka to accomplish this. The architecture itself is composed of three layers: the batch layer, for processing historical data in batches, the speed layer (which handles real time streaming data) and finally, the serving layer (which merges and presents information from both layers). It ensures both accuracy and timeliness, in processing information.
- Delta architecture : A delta architecture is a type of data pipeline structure that simplifies and enhances the lambda architecture by incorporating unified tools and frameworks like Delta Lake, Spark or Databricks. This architecture comprises two layers: the bronze layer (which receives data through streams or batches), the silver and gold layers that process and provide refined data through streams or batches. The same engine and format are used throughout this architecture. They ensure both accuracy and timeliness while also offering reliability and scalability.
Data pipeline vs ETL (Extract Transform Load) pipeline
A data pipeline is a term that encompasses the movement of data from one place to another regardless of the source, format or destination of the data. When we talk about an ETL pipeline we’re referring to a type of data pipeline that involves three key processes: extraction, transformation and loading.
In an ETL pipeline data is extracted from sources like web pages, applications, sensors or files. Then it is transformed into an desired format such as JSON, XML, CSV or HTML. Finally the transformed data is loaded into a data warehouse like Redshift, Snowflake or BigQuery. ETL pipelines are particularly useful, for dealing with semi structured data and for achieving comprehensive integration and consolidation of information.
Conclusion
In conclusion, data pipeline architectures are the backbone of any data-driven business application. They define how data is collected, processed, and delivered from various sources to various destinations, such as databases, dashboards, or reports.
Data pipeline architectures enable businesses to access, analyze, and utilize data in a more efficient and effective way. They can be designed based on the business needs and goals, and they can have different types, such as streaming pipeline, lambda architecture, or delta architecture.
Integrate your company seamlessly into the pinnacle of data pipelines – harness our services for unparalleled data efficiency and optimization! Start with free trial!