
In todays evolving digital landscape the effective gathering, converting and loading of data are highly prized, especially within the realm of web scraping. An ETL pipeline plays a role in preparing data enabling the extraction of valuable information from unprocessed web data for tech enthusiasts and professionals alike.
This piece delves into the intricacies of ETL pipelines highlighting their significance, in web scraping scenarios and empowering readers with the know how to make the most of their functionalities.
What is ETL Pipeline?
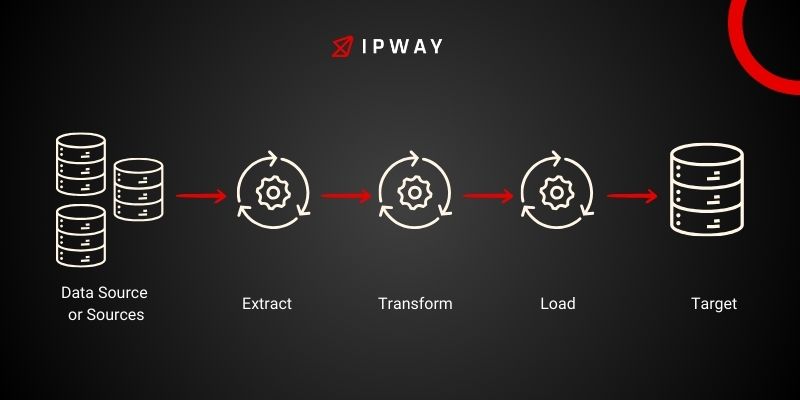
In the realm of data handling in the world of web scraping we find the ETL pipeline. This methodical way of managing data encompasses Extract, Transform and Load. It plays a role, in turning unrefined data from various online origins into an organized and practical form. Lets explore each step of the ETL pipeline further to grasp its importance and how it works.
Extract
The data journey kicks off with the extraction phase. The main aim here is to gather data from its sources accurately and smoothly. In the world of web scraping these sources mainly consist of websites and online platforms. Navigating through these terrains during the extraction process requires skill due, to the diverse structures, dynamic content and access limitations encountered.
When gathering information data can come in forms like HTML from websites JSON from APIs or XML feeds. The difficulty doesn’t only involve gathering this data but also making sure it’s accurate and comprehensive. Methods such, as web crawling and focused scraping are utilized, often needing tools and scripts to navigate intricate web layouts and retrieve necessary details without breaching usage guidelines or overloading the source servers.
Transform
After data extraction the next step involves transforming the data. This stage focuses on converting data into a format that is easier to work with which is essential, for aligning the data with the intended structure and preparing it for analysis. Transformation can involve a multitude of steps, including:
Cleaning: Enhancing data quality involves eliminating entries rectifying mistakes and addressing any missing information.
Normalization: Standardizing formats (e.g., dates and numerical values) to ensure consistency across the dataset.
Enrichment: Enhancing the dataset by incorporating information, from various origins or calculated measurements to boost its worth.
Filtering: Choosing the necessary sections of the information that cater to the projects particular requirements.
Aggregation: Condensing information by computing averages or sums to aid in advanced analysis.
The adaptation phase is flexible relying greatly on the needs of how the data will be utilized in the end. It demands a comprehension of both the original data and the desired format to guarantee that the data is not only usable but also tailored for analysis or storage purposes.
Load
During the load phase the data that has been transformed is relocated to its destination all set for retrieval, examination and decision making purposes. This step includes moving the data into a storage system, which could vary from databases and data warehouses to cloud storage options or even plain files such as CSVs or JSON. The selection of storage method is influenced by aspects, like the amount of data the speed at which access is needed and the analytical instruments that will be utilized later on.
Large amounts of data can be loaded in batches, known as batch loading when immediate processing is not necessary. Alternatively for applications that rely on real time data updates stream loading can be used to ensure the latest information is available.
During this process it is crucial to maintain the security and integrity of the data both during transfer. Once it has been moved to its new destination. This often involves implementing encryption methods and validating the data to prevent any issues.
What are the different types of ETL Pipelines?
ETL pipelines, although they follow the steps of Extract, Transform and Load can be customized and put into practice in various ways to meet specific project needs, data quantities and real time data handling demands.
It is essential to grasp the ETL pipeline variations to choose the best approach, for your data processing assignments particularly in situations involving web scraping. Here’s a closer look at the primary types of ETL pipelines:
Batch ETL Pipeline
Batch ETL processes involve handling data in chunks at set times rather than continuously. This approach works well when real time data processing isn’t necessary allowing data to be gathered and processed in bulk. Typically batch processing occurs during quieter periods to avoid straining system resources and performance.
Batch ETL pipelines offer simplicity and reliability for managing extensive datasets that don’t need immediate analysis. They provide error handling and quality checks before loading data into the destination system. However there’s a delay between collecting data and making it available for use, which may not be ideal, for time tasks.
Real-time ETL Pipelines
In comparison to batch processing, real time ETL pipelines are specifically designed to manage data streaming by processing data in time as it becomes accessible. This method is crucial for applications that require data processing, such as monitoring systems, fraud detection and dynamic pricing models.
Real time ETL pipelines involve architectures and technologies including streaming data processing engines and in memory data storage to efficiently handle the constant flow of data, with minimal delays. While these pipelines can offer actionable insights they demand a sturdy infrastructure and effective error handling mechanisms to uphold data integrity and performance.
Cloud-based ETL Pipelines
The popularity of cloud computing has led to a surge in the use of cloud based ETL pipelines, which offer scalability, flexibility and cost effectiveness. These pipelines utilize cloud services to handle ETL tasks enabling adjustments for data volumes and processing requirements.
Cloud based ETL solutions typically offer a variety of tools for data integration, transformation and loading simplifying pipeline management for organizations without the need for investments in, on premises hardware.
Cloud based ETL solutions are attractive, to companies aiming to reduce infrastructure expenses. For endeavors needing quick implementation and scalability. Additionally they take advantage of cloud service providers continuous upkeep and enhancements guaranteeing that ETL operations stay effective and aligned with cutting edge technologies.
Streaming ETL Pipelines
Real time ETL involves a type of ETL known as streaming ETL pipelines, which are tailored to manage streaming data sources like live social media feeds, sensors and IoT devices. These pipelines excel at handling data in motion by processing, transforming and loading data from diverse origins.
Handling streaming ETL pipelines necessitates utilizing technologies of handling large amounts of data in a decentralized manner ensuring swift and efficient data processing. These tools play a role, in situations where real time data analysis is essential empowering organizations to respond promptly to unfolding events and emerging trends.
Benefits of ETL Pipelines
ETL pipelines go beyond being a data processing workflow; they play a vital role, in efficient data management and analysis. Through the process of extracting, transforming and loading data ETL pipelines offer numerous benefits to companies by improving data quality supporting decision making and increasing operational efficiency.
Here’s an in-depth look at the key benefits of implementing ETL pipelines, particularly in the context of web scraping and data integration projects:
Enhanced data quality and consistency: ETL pipelines enhance the quality and uniformity of data by refining and standardizing it before transferring it to storage or analytical systems. This step is essential, for web scraping endeavors involving data origins guaranteeing the utilization of top notch data minimizing mistakes and enhancing dependability.
Improved efficiency and automation: ETL pipelines streamline data preparation by automating tasks that would typically require work. They manage extraction schedules. Implement transformation guidelines with little human involvement thereby expediting processing and enabling resources to be allocated to more strategic endeavors such, as data analysis.
Scalability and flexibility: With the expansion of data and evolving requirements ETL pipelines offer the ability to scale and adjust. They can manage data sets incorporate new sources and support various formats as needed. This adaptability enables companies to make use of their data resources without being constrained by their original setups.
Enhanced security and compliance: ETL pipelines enhance data security and compliance by consolidating processing tasks. They incorporate security protocols. Guarantee adherence to regulations by following standardized data procedures creating a trail of audits, for changes and transfers.
Accelerated decision-making: By using ETL pipelines decisions are made faster as they provide organized data. This helps to shorten the time between gathering data and gaining insights which is essential, in dynamic markets to stay ahead of the competition.
ETL Pipeline vs. Data Pipeline
In the field of data management and analytics we often hear about “ETL pipelines” and “data pipelines” being related terms. However they represent ideas with specific purposes and functions. It’s important to grasp the distinction between these two types of pipelines when crafting data management plans particularly in intricate situations like web scraping and extensive data integration initiatives. Lets delve into the features that differentiate ETL pipelines, from data pipelines.
Data Pipeline
A data pipeline encompasses a series of processes that manage the movement of data from sources to a designated location, for storage, analysis or additional processing. It covers the data lifecycle, including gathering, transferring, changing and storing data. These pipelines are created to automate the movement of data guaranteeing its transition through different processing stages as required.
Data pipelines can encompass a movement of data from one location to another or a sophisticated sequence of tasks involving filtering, combining, enhancing and additional functions. They are not constrained by any data format or arrangement and have the capability to manage both organized and unorganized data. The versatility and adjustability of data pipelines establish them as an element of contemporary data frameworks catering to diverse requirements, for data processing and analysis.
ETL Pipeline
The ETL pipeline, which stands for Extract, Transform and Load is a data pipeline that concentrates on extracting data from source systems converting it into an organized and logical format and then transferring it into a target database or data warehouse. This specialized pipeline is part of the data pipeline framework highlighting the transformation phase as a key element, in preparing the data.
The phase of transformation is what really distinguishes the ETL pipeline as it includes a sequence of tasks aimed at cleansing standardizing and enhancing the data to make it suitable for analysis and reporting purposes. This step is crucial in maintaining data quality and coherence especially when amalgamating information from origins, like in projects involving web scraping. ETL pipelines are customized for situations where the reliability and usability of the data’re key factors ensuring that the data fed into the destination system is precise, dependable and primed for insightful examination.
Building an ETL Pipeline with Python: A Comprehensive Guide
Python, with its range of libraries and frameworks is a dominant force in the field of data engineering providing unmatched flexibility and functionality, for creating ETL pipelines. Whether you’re pulling data from the internet manipulating datasets or storing information in databases Python equips you with the resources needed for every step of the ETL journey. Here’s how you can harness Python to build an effective ETL pipeline for your data processing needs:
Step 1: Setting up your environment
Make sure your Python setup has all the required libraries before you start coding. Essential libraries like Requests, BeautifulSoup (for parsing HTML) Pandas (for manipulating data) and SQLAlchemy (for interacting with databases) are crucial for web scraping and ETL tasks. It’s advisable to use an environment, for better dependency management.
Step 2: Extracting data
Web Scraping for data extraction
The extraction phase involves retrieving data from your sources. For web scraping, you’ll typically use the Requests library to make HTTP requests to the target website and BeautifulSoup to parse the HTML content, extracting the data you need.
import requests
from bs4 import BeautifulSoup
def extract(url):
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
return soup
Ensure you comply with the website’s terms of service and robots.txt file to avoid any legal issues or access problems.
Reading from APIs or Databases
For data sources accessible via APIs, the requests library can also be used to handle API requests. When dealing with databases, libraries like SQLAlchemy or PyODBC can facilitate data extraction directly from relational databases.
Step 3: Transforming data
During the transformation phase, data undergoes. Processing to prepare it for analysis. Pandas plays a role in this stage providing a variety of features to manipulate data effectively.
mport pandas as pd
def transform(raw_data):
# Convert raw HTML data to a structured format, e.g., DataFrame
data = pd.DataFrame(raw_data, columns=['Column1', 'Column2'])
# Perform cleaning operations such as removing duplicates, filling missing values, etc.
data_cleaned = data.drop_duplicates().fillna(value="N/A")
return data_cleaned
This phase may involve complex logic, depending on the quality of the source data and the requirements of the target schema.
Step 4: Loading data
After you’ve converted your data the next step is to transfer it to a location, such, as a file system, database or data warehouse. When dealing with databases SQLAlchemy can simplify many of the tasks related to database operations.
from sqlalchemy import create_engine
def load(data_frame, database_uri, table_name):
engine = create_engine(database_uri)
data_frame.to_sql(table_name, engine, index=False, if_exists='append')
This step may involve considerations around performance and data integrity, such as batch loading or transaction management, to ensure data is loaded efficiently and correctly.
Step 5: Orchestrating the pipeline
Setting up the ETL pipeline includes arranging a scheduler to automate running your ETL tasks. Tools, like Apache Airflow or Prefect can be utilized to outline workflows, schedule tasks and keep track of the pipelines well being and efficiency.
Conclusion
ETL pipelines play a role in the realm of web scraping providing a systematic method for getting data ready that improves effectiveness and accuracy. Embracing and utilizing ETL pipelines allows technology enthusiasts to harness the power of web scraped data opening doors to deep analyses and well informed choices. Whether you’re new, to this or a seasoned expert honing your skills in ETL pipelines holds importance in todays data focused environment.