
CAPTCHAs, also known as Automated Public Turing tests to differentiate Computers and Humans, can be found everywhere on the web. These security measures are created to safeguard websites from automated bots, by offering tasks that are simple for humans to complete but tricky for automated systems. Although CAPTCHAs play a role in upholding the reliability and safety of websites they can present hurdles for developers involved in web scraping, automation and other online tasks that demand smooth access, to data.
This article offers a tutorial on how to bypass CAPTCHA challenges through different methods, particularly highlighting the usage of Web Unblocker with Python. After going through this guide you will grasp the techniques on how to bypass CAPTCHA and enhance the efficiency of your automation tasks.
How Does a CAPTCHA Work?
CAPTCHAs are created to tell apart users from automated bots by using tasks that humans can do effortlessly but are tricky for bots. The idea is straightforward: introduce a challenge that’s hard for a computer to tackle but simple for a human. There are several types of CAPTCHAs, each employing different methods to achieve this goal:
Text-based CAPTCHAs: Users are asked to enter a series of letters and numbers displayed in an image. The distortion is intentionally created to hinder optical character recognition (OCR) software, from interpreting the text.
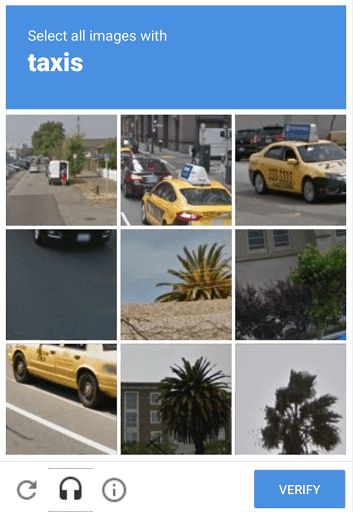
Image-based CAPTCHAs: Users are asked to select images that match a given description. For example, users might be asked to click on all images containing traffic lights. This type of CAPTCHA leverages human visual recognition capabilities.
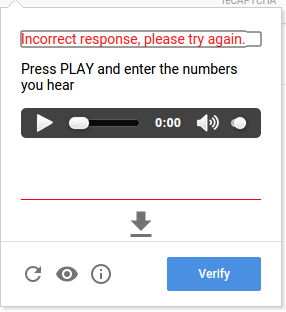
Audio CAPTCHAs: For individuals, with impairments audio CAPTCHAs involve listening to a series of letters or numbers and then entering them correctly. This method demands audio processing skills to overcome the challenge.
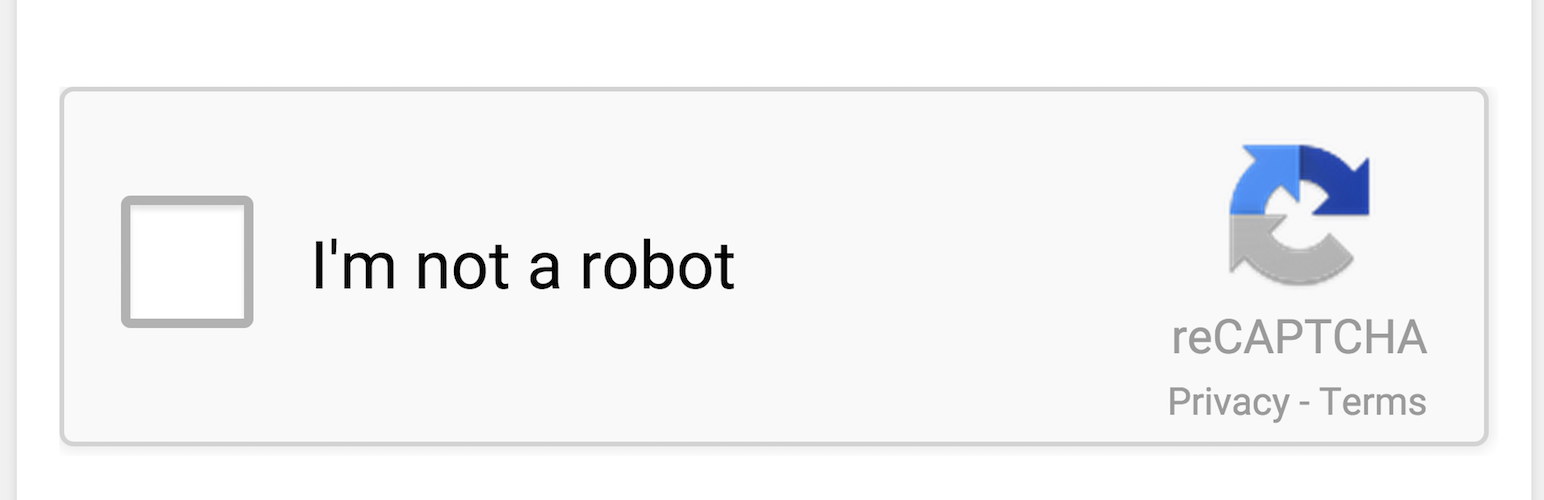
ReCAPTCHA: Created by Google ReCAPTCHA frequently asks individuals to complete actions, like clicking a checkbox that says “I am not a robot” or solving intricate image based challenges. ReCAPTCHA utilizes machine learning techniques to distinguish between humans and automated bots.
Underlying Techniques
CAPTCHAs employ methods to enhance their efficiency. They incorporate image identification, analysis and AI algorithms. Having an insight, into these processes enables developers to grasp the complexities of circumventing CAPTCHAs and devise better tactics to conquer them effectively.
How to Bypass CAPTCHA with Web Unblocker Using Python
Getting around CAPTCHAs may pose a challenge. With the appropriate tools and methods it can be achieved. Web Unblocker stands out as a tool providing a proxy solution, for bypassing CAPTCHAs and other anti bot measures. Here’s how you can use Web Unblocker with Python to bypass CAPTCHAs:
Setting Up Web Unblocker
Firstly you must register for a Web Unblocker membership. Acquire your unique API key. Web Unblocker streamlines the procedure of bypassing CAPTCHAs by managing the obstacles and offering a browsing experience. Follow these steps to set up Web Unblocker with Python:
Install Required Libraries:
Make sure you’ve got all the required Python libraries set up. You’ll need requests to handle HTTP requests and json to manage JSON data.
pip install requests
Configure Web Unblocker in Python:
Now, let’s set up a Python script to use Web Unblocker. This involves defining your API key, the target URL you want to access, and configuring the request headers.
import requests
# Your Web Unblocker API key
api_key = 'YOUR_API_KEY'
# Target URL
url = 'https://example.com'
# Web Unblocker endpoint
web_unblocker_url = 'https://api.webunblocker.com'
# Headers for the request
headers = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {api_key}'
}
# Payload for the request
payload = {
'url': url
}
Make the Request:
After setting up the configuration as instructed earlier proceed to send a request to the Web Unblocker API. The Web Unblocker will then process this request bypass the CAPTCHA and provide access, to the requested content.
# Making the request to Web Unblocker
response = requests.post(web_unblocker_url, headers=headers, json=payload)
# Check the response
if response.status_code == 200:
data = response.json()
print('Successfully bypassed CAPTCHA:', data)
else:
print('Failed to bypass CAPTCHA:', response.text)
In this scenario the Web Unblocker deals with the request by addressing any CAPTCHA challenges that come up. The reply from Web Unblocker will include the information, from the desired URL if the CAPTCHA was effectively bypassed.
Handling the Response:
Upon receiving a reply from Web Unblocker you are free to move forward with handling the data as required. This could entail analyzing HTML content retrieving details or storing the information, for future examination.
if response.status_code == 200:
data = response.json()
# Process the data
content = data.get('content')
print('Page Content:', content)
else:
print('Failed to retrieve content:', response.text)
Benefits of Using Web Unblocker
Simplicity: Web Unblocker makes it easier to bypass CAPTCHAs by managing the details internally so you can concentrate on your main responsibilities.
Reliability: Web Unblocker offers a solution, for accessing content hidden behind CAPTCHAs by using sophisticated proxy methods.
Scalability: Whether you’re tackling a project or diving into a big endeavor Web Unblocker is adaptable to match your requirements making it a versatile option, for a range of uses.
Best Practices
API Key Security: Remember to protect your API key and refrain from embedding it directly into your scripts. Instead opt for using environment variables or secure storage options.
Rate Limiting: Remember to pay attention to the speed restrictions set by Web Unblocker and the destination site to prevent getting blocked or marked as spam.
Error Handling: Make sure to include error handling in your scripts to handle possible problems, like network issues, incorrect responses or hitting rate limits.
How to Solve CAPTCHA Tests
Although tools such as Web Unblocker can be helpful it’s also advantageous to know strategies, for tackling CAPTCHA challenges. Below are a few approaches:
Optical Character Recognition (OCR)
OCR technology has the capability to crack text based CAPTCHAs. You can incorporate tools such as Tesseract into your Python scripts to automate this task. OCR functions, by examining the shapes and designs of the characters in an image and transforming them into text that machines can understand.
from PIL import Image
import pytesseract
# Load CAPTCHA image
image = Image.open('captcha_image.png')
# Use Tesseract to extract text
captcha_text = pytesseract.image_to_string(image)
print('CAPTCHA text:', captcha_text)
Machine Learning
Training machine learning algorithms to identify and solve CAPTCHAs involves using a set of CAPTCHA images along with their solutions. By utilizing tools such as TensorFlow or PyTorch you can. Teach models to accurately determine the solutions, for various CAPTCHA puzzles.
Here’s a simplified example using TensorFlow:
import tensorflow as tf
from tensorflow.keras import layers, models
# Define a simple convolutional neural network (CNN)
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(height, width, 1)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dense(num_classes, activation='softmax')
])
# Compile the model
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# Train the model
model.fit(training_images, training_labels, epochs=5, validation_data=(validation_images, validation_labels))
# Use the trained model to predict CAPTCHA text
predicted_text = model.predict(captcha_image)
print('Predicted CAPTCHA text:', predicted_text)
This approach demands computational power and a properly annotated dataset yet it proves to be quite efficient, in tackling intricate CAPTCHAs.
Human-Based Solutions
When automated systems are ineffective human operated CAPTCHA solving services can be utilized. These services involve individuals solving CAPTCHAs in real time. While this approach may result in delays and incur expenses it guarantees a high level of accuracy. Platforms such, as 2Captcha and Anti Captcha provide APIs that can be incorporated into your Python scripts.
import requests
api_key = 'YOUR_2CAPTCHA_API_KEY'
captcha_image = 'path/to/captcha_image.png'
# Send CAPTCHA image to 2Captcha
response = requests.post('http://2captcha.com/in.php', files={'file': open(captcha_image, 'rb')}, data={'key': api_key, 'method': 'post'})
if response.status_code == 200:
captcha_id = response.text.split('|')[1]
print('CAPTCHA ID:', captcha_id)
# Retrieve CAPTCHA solution
result_url = f'http://2captcha.com/res.php?key={api_key}&action=get&id={captcha_id}'
solution_response = requests.get(result_url)
if solution_response.status_code == 200 and 'OK' in solution_response.text:
solved_text = solution_response.text.split('|')[1]
print('Solved CAPTCHA text:', solved_text)
else:
print('Failed to retrieve CAPTCHA solution:', solution_response.text)
else:
print('Failed to submit CAPTCHA:', response.text)
Browser Automation
Selenium, a tool commonly used for automating browser tasks has the capability to perform actions like clicking buttons entering text and choosing items on a webpage. It is frequently employed in conjunction, with CAPTCHA solving services to tackle intricate tasks.
Example using Selenium and a CAPTCHA solving service:
from selenium import webdriver
import requests
# Setup Selenium WebDriver
driver = webdriver.Chrome()
# Navigate to the target website
driver.get('https://example.com')
# Screenshot the CAPTCHA
captcha_element = driver.find_element_by_id('captcha')
captcha_element.screenshot('captcha_image.png')
# Use 2Captcha to solve the CAPTCHA
api_key = 'YOUR_2CAPTCHA_API_KEY'
captcha_image = 'captcha_image.png'
response = requests.post('http://2captcha.com/in.php', files={'file': open(captcha_image, 'rb')}, data={'key': api_key, 'method': 'post'})
if response.status_code == 200:
captcha_id = response.text.split('|')[1]
print('CAPTCHA ID:', captcha_id)
result_url = f'http://2captcha.com/res.php?key={api_key}&action=get&id={captcha_id}'
solution_response = requests.get(result_url)
if solution_response.status_code == 200 and 'OK' in solution_response.text:
solved_text = solution_response.text.split('|')[1]
print('Solved CAPTCHA text:', solved_text)
# Fill in the CAPTCHA solution
captcha_element.send_keys(solved_text)
driver.find_element_by_id('submit_button').click()
else:
print('Failed to retrieve CAPTCHA solution:', solution_response.text)
else:
print('Failed to submit CAPTCHA:', response.text)
Conclusion
Bypassing CAPTCHAs can be quite a challenge. Its a necessary skill for developers who are involved in web scraping and automation tasks. Having a grasp of how CAPTCHAs function and using the appropriate tools and methods can really boost your productivity.
Web Unblocker, when used alongside Python provides an approach, to dealing with CAPTCHA hurdles. Moreover tapping into OCR technology machine learning algorithms, human based solutions and browser automation can give you more power to tackle these challenges effectively.
When you master these techniques your web scraping and automation tasks will run smoothly and efficiently. This way you can concentrate on extracting data without being slowed down by security measures. Although overcoming CAPTCHAs may pose a challenge using the methods and tools can help simplify and speed up the task.
By adhering to the suggestions and illustrations outlined in this article you will be well equipped to handle CAPTCHA tests with assurance and enhance the efficiency of your automated processes. This information holds significance not for boosting your work output but also for grasping the constantly changing realm of online security and automation. Whether you are a programmer or new to web scraping and automation becoming adept at bypassing CAPTCHAs is a vital milestone on the path, to accomplishing your objectives.
Take your data scraping to the next level with IPWAY’s datacenter proxies!