
Web scraping has become a tool for collecting information from the internet particularly in the competitive job market. By web scraping jobs data from Google companies and individuals can acquire information about job trends, salaries and the need, for different skills. This manual will guide you through the steps of gathering Google job listings using Python offering an approach to help you efficiently retrieve relevant data.
Benefits of Web Scraping Jobs Data on Google
Web scraping jobs postings from Google offers numerous advantages:
Real-Time Data: Check out the recent job listings and stay updated on the latest trends to make sure you have up, to date and pertinent information.
Market Analysis: Undersøg arbejdsmarkedstendenser for at identificere efterspurgte færdigheder og nye jobroller.
Competitive Intelligence: Keep an eye on what your competitorsre posting for job openings and their hiring patterns to stay ahead in the market.
Automation: Streamline the task of collecting employment information resulting in time and resource savings when compared to manual data gathering.
Custom Insights: Customize the gathered information to meet requirements enabling profound and distinctive perspectives, on the employment landscape.
Google Jobs Website Overview
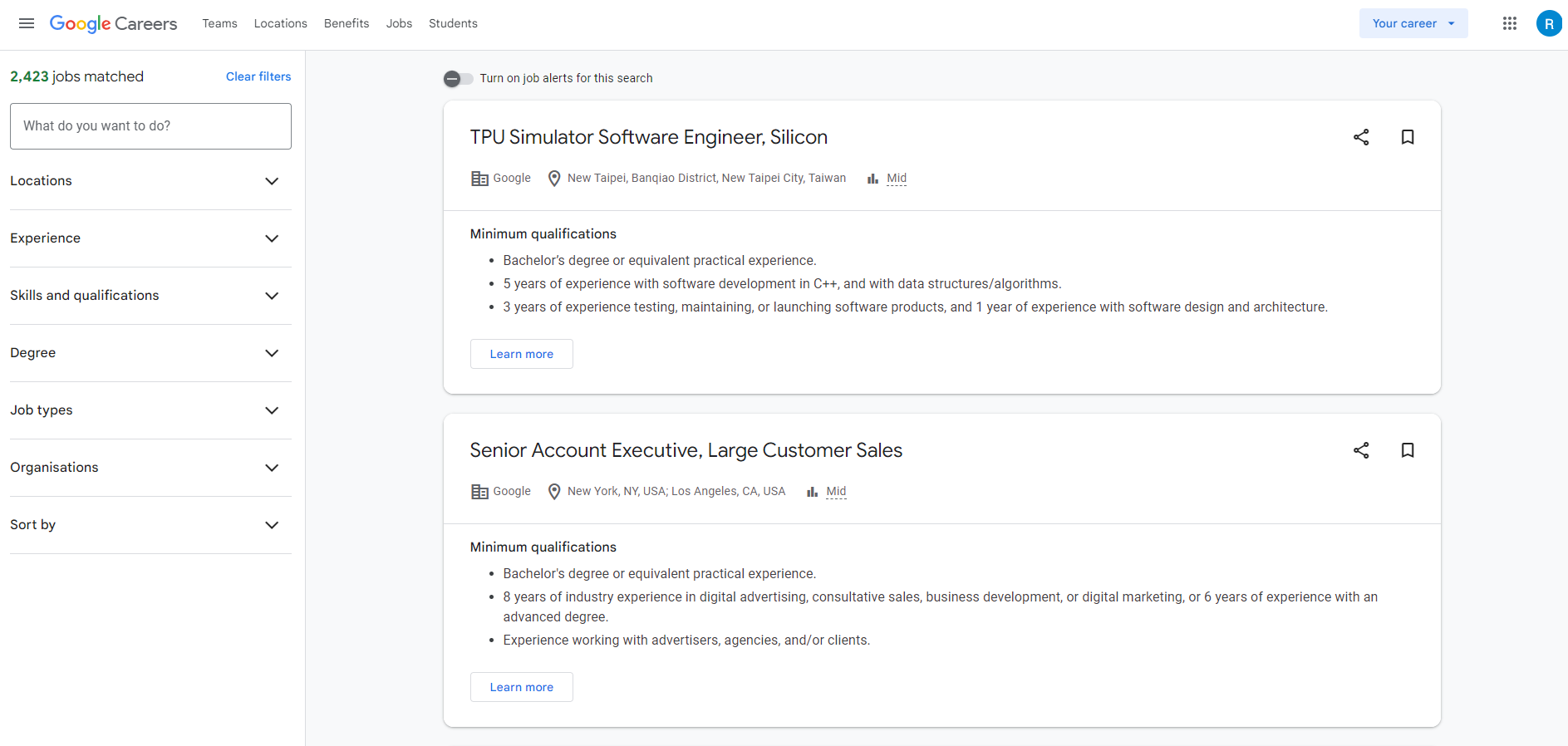
Google Jobs is a tool on Google Search that gathers job postings from different websites. It offers users a way to browse job listings right on the Google search results page. Having a grasp of how Google Jobs works is important for efficient web scraping jobs. This segment will give you a look at Google Jobs pointing out its main functions, user interface and the essential aspects, for web scraping purposes.
Key Features of Google Jobs
Aggregated Listings: Google Jobs gathers job listings from places such, as corporate websites, job boards and staffing firms. This collection offers individuals a selection of job options all in one location.
Advanced Search Filters: Job seekers have the option to narrow down their job hunt by utilizing filters, like job title, location, posting date, business category and other criteria. These filters assist users in discovering the most suitable job postings.
Job Alerts: Users have the option to create job alerts tailored to their preferences, which will notify them when new job listings that meet their requirements are available.
Company Reviews and Ratings: Reviews and ratings from platforms such as Glassdoor and Indeed offer additional information, about prospective employers.
Salary Information: Google Jobs often provides estimated salary ranges for a variety of job listings, which can assist individuals in gaining insight into the compensation offered for various positions.
Elements Important for Web Scraping Jobs
When scraping data from Google Jobs it’s crucial to grasp the HTML layout and pinpoint the components housing the information you need. Here are the key elements present, in Google Jobs listings HTML:
- Job Title: Typically found within an h2 or h3 tag, with classes.
- Company Name: The company name is typically located within a span or div tag often identified by a class.
- Location: The job location is usually specified within a div or span tag.
- Job Description: The primary information, in the job listing is typically found within a div or section tag.
- Posting Date: Details regarding the posting date of the job are typically located within a tag labeled with a class that specifies either the date or time.
- Application Links: Links, for job applications are typically found within anchor (a) tags.
<div class="BjJfJf">
<h2 class="job-title">Data Scientist</h2>
<div class="company-name">Tech Corp</div>
<div class="location">New York, NY</div>
<div class="job-description">
We are looking for a skilled Data Scientist to join our team...
</div>
<div class="posting-date">Posted 3 days ago</div>
<a href="https://company.com/apply" class="application-link">Apply</a>
</div>
In the given instance the div identified as BjJfJf symbolizes a job listing. Inside this div you can find details such as the job title, company name, location, job description, posting date and a link, for submitting applications.
Libraries and Tools for Scraping Google Jobs
To gather job postings from Google you need to use a mix of Python libraries and tools to manage web requests analyze HTML content organize data and automate interactions with browsers. Here’s a comprehensive overview of the essential libraries and tools you’ll need:
Requests
The requests library in Python is a user HTTP library designed with simplicity and sophistication in mind. It enables users to send HTTP requests and manage the responses making it ideal, for fetching the HTML content of websites.
Installation: You can install requests using pip:
pip install requests
Usage Example:
import requests
url = "https://www.google.com/search?q=data+scientist+jobs+in+New+York"
response = requests.get(url)
html_content = response.text
BeautifulSoup
BeautifulSoup is a tool commonly employed to analyze HTML and XML content. It generates a representation of processed web pages enabling the retrieval of information from HTML, particularly beneficial, for extracting data from websites.
Installation: You can install BeautifulSoup with pip:
pip install beautifulsoup4
Usage Example:
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_content, 'html.parser')
job_titles = soup.find_all('h2', class_='job-title')
Selenium
Selenium proves to be a tool for managing web browsers via scripts and executing browser automation tasks. It comes in handy for extracting updated content (using JavaScript) that isn’t present, in the initial HTML source code.
Installation: Install Selenium with pip:
pip install selenium
You will also need a WebDriver (like ChromeDriver for Google Chrome).
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
options = Options()
options.headless = True # Run in headless mode
service = Service('path/to/chromedriver')
driver = webdriver.Chrome(service=service, options=options)
driver.get(url)
page_content = driver.page_source
driver.quit()
Pandas
Pandas, an open source library for data manipulation and analysis provides data structures like DataFrames that are ideal for organizing editing and examining structured data sets such, as job postings.
Installation: Install Pandas with pip:
pip install pandas
Usage Example:
import pandas as pd
data = {
'Title': ['Data Scientist', 'Software Engineer'],
'Company': ['Tech Corp', 'Innovate LLC'],
'Location': ['New York, NY', 'San Francisco, CA']
}
df = pd.DataFrame(data)
df.to_csv('job_listings.csv', index=False)
SerpAPI
SerpAPI is an API created for extracting search engine outcomes, such, as Google Jobs. It streamlines the procedure by offering organized data from Google search results without requiring HTML parsing.
Installation: You can use SerpAPI by signing up for an API key and installing the client library:\
pip install google-search-results
Usage Example:
from serpapi import GoogleSearch
params = {
"engine": "google_jobs",
"q": "data scientist in New York",
"api_key": "YOUR_API_KEY"
}
search = GoogleSearch(params)
results = search.get_dict()
Add Your API User Credentials
To view job openings at Google using SerpAPI you must first sign up. Get your API credentials. These credentials are vital, for verifying your requests to the API.
import os
API_KEY = os.getenv('SERPAPI_KEY') # Store your API key in an environment variable for security
Set Up Queries and Locations
Specify the search criteria, such as the job title and location. These specifications will form the basis, for creating the search queries to be forwarded to the API.
job_title = "data scientist"
location = "New York"
Prepare the API Payload with Parsing Instructions
Prepare the data package, for the API request containing all the search criteria and essential information. Send this package to SerpAPI to fetch the listings of jobs.
import requests
def get_job_listings(job_title, location):
url = "https://serpapi.com/search.json"
params = {
"engine": "google_jobs",
"q": f"{job_title} in {location}",
"api_key": API_KEY,
}
response = requests.get(url, params=params)
return response.json()
Define Functions
Create functions that analyze job postings and retrieve information. These functions are designed to handle the data, from the API and organize it in a practical way.
from bs4 import BeautifulSoup
def parse_job_listings(job_data):
jobs = []
for job in job_data.get('jobs_results', []):
job_info = {
"title": job.get("title"),
"company": job.get("company_name"),
"location": job.get("location"),
"description": job.get("description"),
"posted_date": job.get("detected_extensions", {}).get("posted_at"),
}
jobs.append(job_info)
return jobs
Create the main() Function
Consolidate all the tasks into one function to manage the web scraping jobs process. This main function will oversee the process starting from sending the API request to storing the retrieved data.
import pandas as pd
def main():
job_data = get_job_listings(job_title, location)
jobs = parse_job_listings(job_data)
df = pd.DataFrame(jobs)
df.to_csv("google_job_listings.csv", index=False)
print("Job listings saved to google_job_listings.csv")
if __name__ == "__main__":
main()
Run the Complete Code
Run the code to gather the job postings and store them in a CSV file. Double check that your API key is configured properly and that all required libraries are installed.
pip install requests beautifulsoup4 pandas
python scrape_google_jobs.py
Conclusion
Web scraping jobs from Google using Python is a method that offers businesses and individuals helpful insights into the job market. Automating data collection saves time and resources providing up to date details, on job trends, salary levels and skill demand. This guide has covered everything from grasping Google Jobs framework to configuring your web scraping jobs setup and coding requirements.
By using Python libraries like BeautifulSoup and Requests along with APIs such as SerpAPI you can effectively. Analyze job information. This helps you stay competitive in the job market make decisions based on data and better grasp job trends. Moreover delving into areas like dealing with dynamic content and overseeing extensive data scraping can boost your scraping skills and ensure adherence, to legal and ethical guidelines.
By using tools and methods extracting job postings from Google, can be a valuable addition to your data analysis resources. It offers insights to help you thrive and adapt in todays dynamic job market.
Take your data scraping to the next level with IPWAY’s datacenter proxies!