
Introducing web scraping Playwright: an automation tool created by Microsoft that is set to revolutionize web scraping with its powerful and user friendly platform for automating web browsers. This thorough guide explores all aspects of Playwright covering everything from its principles to real world applications, in web scraping ensuring a comprehensive grasp of its capabilities and benefits.
In todays world overflowing with data it’s important to accurately access a vast amount of information especially for businesses looking to stay ahead. Web scraping has become a method for extracting data providing valuable insights that influence important decision making processes.
This article explores the capabilities of Playwright showcasing its flexibility, in automating tasks and extracting data from websites.
What Is Playwright?
Playwright is a testing and automation framework that excels in simplifying interactions with web browsers. It allows you to create scripts that control how the browser behaves giving you access to a range of browser functions.
Using Playwright automation scripts can smoothly move through URLs enter text click buttons extract information and more. One standout feature is its capability to manage pages simultaneously avoiding obstacles and eliminating the need, for waiting times. By utilizing Playwrights browser based requests it’s even possible to bypass CAPTCHAs.
It works well with web browsers like Google Chrome, Microsoft Edge (using Chromium) and Firefox. Safari is also supported with WebKit. Playwright is great for automating web tasks across browsers and platforms. Additionally it supports programming languages such as Node.js, Python, Java and.NET giving developers the flexibility to choose their preferred language, for automating websites.

Playwright offers a range of documentation starting from beginners guides to detailed explanations of its features making it easier for users at any point, in their automation learning process.
Why Use Playwright?
Web scraping is an activity, particularly in the realm of JavaScript, where utilities such, as Cheerio, Selenium, Puppeteer and Playwright make the task more efficient.
Powerful Locators
By using locators that come with built in auto waiting and retry features Playwright effectively chooses elements on web pages. This auto waiting feature simplifies the process of web scraping code by removing the requirement, for manual waiting while pages are loading.
Furthermore the retry mechanism in Playwright makes it ideal for extracting information, from single page applications (SPAs) that update content dynamically after the initial page load.
Multiple Locator Methods
When using locators Playwright provides the flexibility to choose elements on a webpage using different syntax options. These options include CSS selector syntax, XPath syntax and even the content of the elements text. Additionally you can refine locators by applying filters to improve their accuracy, for selecting elements.
Web Scraping Playwright
When using locators Playwright provides the flexibility to choose elements on a webpage using different syntax options. These options include CSS selector syntax, XPath syntax and even the content of the elements text. Additionally you can refine locators by applying filters to improve their accuracy, for selecting elements.
Step 1: Installation
To begin using Playwright for web scraping, you first need to set up your environment. Installation is straightforward with Node.js:
npm i playwright
You can set up Playwright. Download browser executables, for Chromium, Firefox and WebKit allowing you to test on various browsers.
Step 2: Launching a Browser
Once installed, you can write a script to launch a browser. Here’s how you initiate a headless browser session, which is preferred for server environments and automation scenarios where no UI is needed:
const { chromium } = require('playwright'); // or firefox, webkit
(async () => {
const browser = await chromium.launch({
headless: true // Set false if you need a UI
});
// other actions...
await browser.close();
})();
Step 3: Navigating Pages
After launching the browser, the next step is to open a new page and navigate to the URL from which you want to scrape data:
const page = await browser.newPage();
await page.goto('https://example.com');
Step 4: Extracting Data
When it comes to retrieving information Playwright offers a range of techniques, for choosing and engaging with elements.
const data = await page.innerText('selector');
console.log(data);
If you need to select from a dropdown before scraping, you can simulate user interaction like so:
await page.selectOption('select#your-dropdown', { label: 'Option Label' });
// Follow up with scraping as the page updates based on the selection
Step 5: Handling Data
After you’ve finished extracting the information you might have to handle or save your data. Lets keep it simple and say we’re recording the extracted information. You could also choose to store it in a file or database instead.
console.log('Extracted Data:', data);
// To save data, simply append/write to a file or insert into a database
Step 6: Closing the Browser
Finally, make sure to close the browser session to free up resources:
await browser.close();
By following these guidelines you can make use of Playwright to efficiently gather information from websites. In this segment we will present an intricate example that integrates browsing, data retrieval and data management to showcase a common web scraping process.
This comprehensive manual not showcases the fundamental functions but also suggests the adaptability of Playwright in managing intricate scraping tasks like handling AJAX loaded information or managing post login sessions, which are prevalent, in numerous contemporary web platforms.
Scraping text
When working with Amazon once the webpage is fully loaded you can utilize a selector to gather all the products by employing the $$eval function.
const products = await page.$$eval('.s-card-container > .a-spacing-base', all_products => {
// run a loop here
})Now all the elements that contain product data can be extracted in a loop:
all_products.forEach(product => {
const title = product.querySelector('.a-size-base-plus').innerText
})At last you can utilize the attribute to retrieve the information, from every data point. Below is the full Node.js code snippet:
const playwright = require('playwright');
(async() =>{
const launchOptions = {
headless: false,
proxy: {
server: 'proxy.ipway.pro:51724',
username: 'ipway_user_name',
password: 'password'
}
};
const browser = await playwright.chromium.launch(launchOptions);
const page = await browser.newPage();
await page.goto('https://www.amazon.com/b?node=17938598011');
await page.waitForTimeout(5000);
const products = await page.$$eval('.s-card-container > .a-spacing-base', all_products => {
const data = [];
all_products.forEach(product => {
const titleEl = product.querySelector('.a-size-base-plus');
const title = titleEl ? titleEl.innerText : null;
const priceEl = product.querySelector('.a-price');
const price = priceEl ? priceEl.innerText : null;
const ratingEl = product.querySelector('.a-icon-alt');
const rating = ratingEl ? ratingEl.innerText : null;
data.push({ title, price, rating});
});
return data;
});
console.log(products);
await browser.close();
})();
The Python code might show some differences. In Python there is a function called eval_on_selector that’s similar to Node.jss $eval but it might not be the best choice for this situation. The issue here is that the second parameter still requires JavaScript. Although this approach could be useful in some situations it would be better to write the code, in Python for this specific case.
Using query_selector and query_selector_all is recommended because they fetch an element and a list of elements respectively.
import asyncio
from playwright.async_api import async_playwright
async def main():
async with async_playwright() as pw:
browser = await pw.chromium.launch(
headless=False,
proxy={
server: 'proxy.ipway.pro:51724',
username: 'ipway_user_name',
password: 'password'
}
)
page = await browser.new_page()
await page.goto('https://www.amazon.com/b?node=17938598011')
await page.wait_for_timeout(5000)
all_products = await page.query_selector_all('.s-card-container > .a-spacing-base')
data = []
for product in all_products:
result = dict()
title_el = await product.query_selector('.a-size-base-plus')
result['title'] = await title_el.inner_text() if title_el else None
price_el = await product.query_selector('.a-price')
result['price'] = await price_el.inner_text() if price_el else None
rating_el = await product.query_selector('.a-icon-alt')
result['rating'] = await rating_el.inner_text() if rating_el else None
data.append(result)
print(data)
await browser.close()
if __name__ == '__main__':
asyncio.run(main())Playwright vs Puppeteer and Selenium
Other tools such as Selenium and Puppeteer are capable of performing similar tasks to Playwright.
However, Puppeteer’s capabilities are constrained in terms of browser and programming language support. It exclusively operates with JavaScript and is compatible solely with Chromium.
Conversely, Selenium accommodates all major browsers and supports a wide array of programming languages. Nevertheless, it is known to be comparatively sluggish and less intuitive for developers.
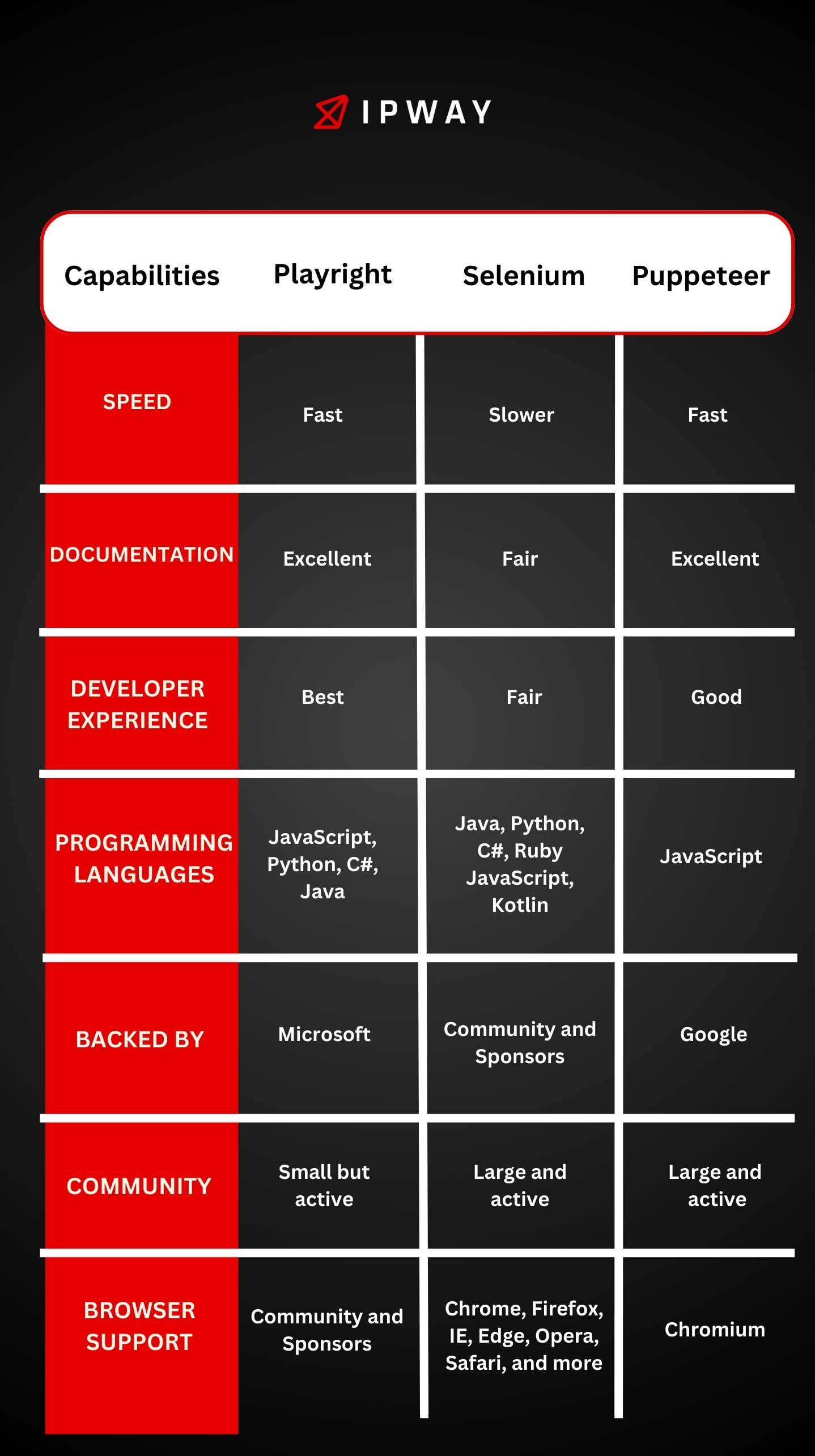
Comparison of performance
As outlined in the preceding section, due to the significant differences in supported programming languages and browsers, conducting a comprehensive comparison across all scenarios proves challenging.
The sole scenario amenable to direct comparison involves scripting in JavaScript for automating Chromium, a combination supported by all three tools.
Delving into an exhaustive comparison lies beyond the scope of this article. For a more in-depth analysis of Puppeteer, Selenium, and Playwright performance, refer to the linked article. However, a key takeaway is that Puppeteer exhibits the fastest performance, closely followed by Playwright, which in certain scenarios outpaces Puppeteer. Selenium emerges as the slowest among the trio.
It’s worth noting that Playwright offers additional advantages, including multi-browser support and compatibility with multiple programming languages.
If your priority is swift cross-browser web automation or if you lack proficiency in JavaScript, Playwright stands as the sole viable option.
Conclusion
Playwright stands out as an asset in the field of web scraping thanks to its powerful automation features that go beyond simple browser testing to include extracting data and engaging with dynamic content on various browsers. As discussed in this guide the adaptability and accuracy of Playwright in replicating interactions make it a crucial tool, for developers and data analysts seeking dependable and effective data gathering options.
Playwright stands out as a tool for web scraping because of its powerful automation features that go beyond just testing browsers to include extracting data and interacting with dynamic content on different browsers. As discussed in this guide Playwrights versatility and accuracy in mimicking interactions make it essential for developers and data analysts seeking reliable data collection solutions. Its wide range of functions such as launching browser sessions navigating web structures and efficiently managing data extraction make it an excellent choice for both beginners and experienced professionals in web scraping. With its compatibility with programming environments and support for major browsers Playwright can meet diverse web scraping needs, whether simple or complex.
Additionally using web scraping Playwright, enables users to handle tasks like interacting with AJAX loaded content, managing cookies and sessions and automating processes in web applications that require login credentials. These capabilities are especially valuable in todays evolving digital landscape where data plays a crucial role, in shaping business strategies and operations.
If you want to utilize web data for business insights or automate interactions with websites effectively Playwright offers a scalable, robust and user friendly solution. It simplifies the hurdles of traditional web scraping methods and opens up new avenues for data driven innovation and efficiency enhancements.
Whether you aim to conduct market research monitor competitor activities or collect data Playwright provides a comprehensive set of tools for achieving reliable results with minimal setup and upkeep. With development and support, from Microsoft Playwright ensures it stays ahead in browser automation technologies.
Uncover how IPWAY’s innovative solutions can transform your web scraping experience, offering a more efficient and effective approach.