
The Internet is vast and it hides a lot of invaluable data. Such information is of utmost importance for many businesses, whether we talk about stock prices, product information, reviews, and everything else. But in order to collect data efficiently, one should not resort to manually copying and pasting text until the end of time.
Thus the art of data collection was born. It’s a complex and important discipline that needs to be properly dealt with, so let’s see what are the most important methods of collecting information across the Web. In this article, we will focus on discussing web scraping and web crawling, the differences between them and the obstacles enterprises need to overcome if they wish to successfully gather data.
Data collecting refers to the process of gathering and measuring data, information, or any variables of interest in a standardised and established manner. This process is based on the importance of the accurate acquisition of data sought by various enterprises and businesses.
Data collection is usually done through web scraping and web crawling. Although they are often considered to be one and the same, you need to learn about the difference between them and the scenarios they are actually used for.
What is Web scraping?
Web scraping refers to the extraction of data from a website. This information is then compiled and given to the user in a structured and accessible format. Basically, it’s just what you used to do in your exam papers. Research, gathering information, and presenting it. But it would be absolutely horrendous to do that manually in such a context.
Therefore, web scraping uses intelligent automation to retrieve vast amounts of data from hundreds, if not thousands of websites across the Internet. This data is exported into a format that is more useful for the user, such as an API or a spreadsheet. Generally speaking, many users make use of a scraping tool.
While the process itself might seem simple, the actual science behind it is rather complex. To put it simply, websites were built for humans to understand, not machines. This is why it’s important that such software collects and gives relevant information.
What is Web scraping used for?
Mastering the art of web scraping will generate fruitful results for companies that wish to gather intelligence and make smarter decisions. Web scraping is important for many use-cases, so let’s list a few of the most prominent ones.
- Price intelligence is regarded as the biggest use case for web scraping
Product and pricing information from e-commerce websites is the bread and butter of many businesses. If an e-commerce company successfully turns this information into intelligence (competitor monitoring, product trend monitoring, and more), then it will surely make better pricing and/or marketing decisions based on data.
- Market research is vital
It goes without saying that being insightful and carefully planning your business strategy will reap many benefits. Therefore, market research should be driven by the most accurate information available. Companies that know how to use high quality, high volume, and highly insightful web scraped data will eventually master business intelligence.
- Lead generation must be carefully considered
Generating leads should be among the top priorities of every business. In the 2020 Hubspot report, 61% of inbound marketers said generating traffic and leads were their most difficult challenge. This is why web scraping is useful, since extraction helps you gain more insight into what’s of your interest.
- Pay attention to brand monitoring
Nowadays, the market competition is fiercer than ever. Consequently, it’s of utmost importance to protect and nurture your online reputation. For example, if you sell your products online, you can use web scraping for reviews and answers to various surveys to analyse how your audience perceives the idea of online shopping, and by extension its view towards the products that you want to sell online.
- Web scraping improves business automation
In some situations, it might be really tedious and time consuming to get access to your database and analyse it, especially if you want to extract the desired information in a well-structured format. This is why it would make sense to use a scraper to do the job for you, as opposed to trying to work your way through complicated internal systems until you find what you need.
- Carefully observe MAPs
Minimum advertised price (MAP) monitoring is important if you want to make sure your brand’s online prices are aligned with your pricing policy. With tons of resellers and distributors, it’s impossible to monitor the prices manually. That’s why web scraping comes in handy, simply because you can keep an eye on your products’ prices.
How does Web scraping work?
Generally speaking, intelligent automation is based on the usage of a web scraping tool, or simply a web scraper. The software is first given a couple of URLs or more to load before scraping. Then, it requests access to the entire HTML code of those web pages and will begin extracting either the entire data or specific information selected by the user.
In most cases, the user will select the specific data they want from that specific web page. This is important because the extracted information needs to be relevant and helpful for the respective company, business, and/or enterprise. For example, you might want to scrape an Amazon product page for prices, but you are not interested in reviews.
Therefore, more advanced software has been gradually implemented in order to facilitate the gathering and analysis of web data. If done correctly, the scraper will export all the data that has been collected into a well-structured and easy to read format. The most common formats are CSV or Excel spreadsheets, while more advanced scrapers, be them web or desktop based, will convert the gathered data into other formats such as the popular JSON, which in turn can be used for an API, without the need of running JavaScript commands.
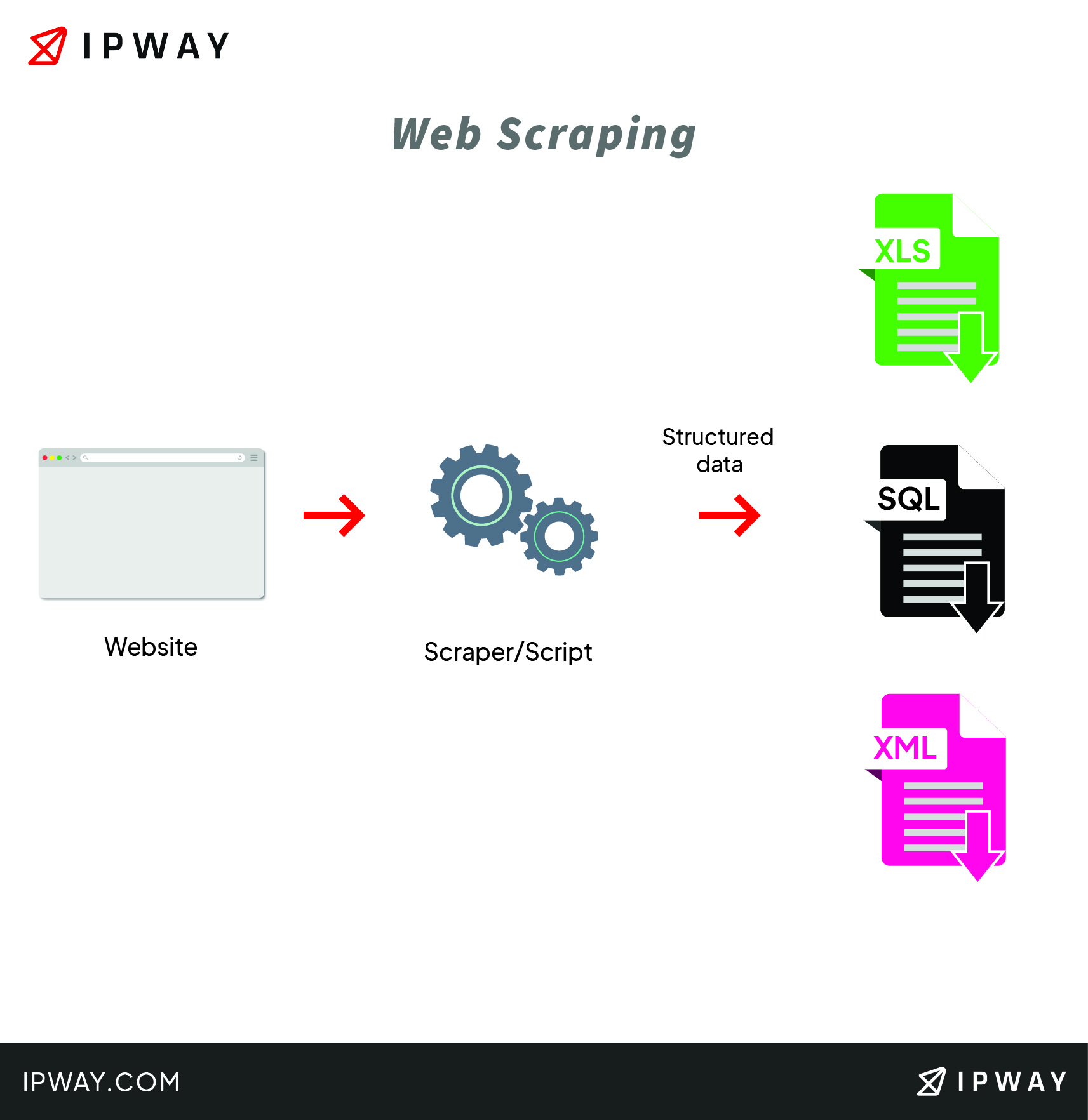
How can you scrape websites?
On a case-by-case basis, such tools differ quite drastically from one another. Comparing these tools can be unnecessarily complicated, so for now let’s discuss them from some basic perspectives.
- You can download and use a pre-built web scraper
You don’t need much to start the process of web scraping. All you have to do is Google a pre-built web scraper. There are many programs that you can download and run right away and most of them have advanced, useful features such as scrape scheduling, exporting into different formats, and more. You can, for example, download popular desktop-based web scrapers like Octoparse, ScrapingBot, or Import.io.
- You can use a browser extension
Choosing to add a web scraper as an extension to your browser means two things:
Firstly, it is more convenient and easy to use because you integrate the scraper right into your desired browser; Among the most popular you can find Data Scraper for Chrome, Webscraper.io, Scraper for Chrome, or Outwit hub for Firefox;
Secondly, it is drastically affected by your browser’s limitations. Any advanced features that would have to be used or happen outside of the browser would be impossible to implement. For example, IP rotations would not be possible in this kind of extension.
If you opt for a web scraper as dedicated computer software, you get rid of all the limitations your browser might have. While it’s true it’s not as easy and convenient to install and configure, such software makes up for this by having a lot of advanced features that you can significantly benefit from.
Additionally, you could use Web-based scraping applications as a bridge between the above. Common examples include Dexi.io (also known as Cloud scrape), or Webhose.io.
- You can build your own web scraper
On the other hand, no one ever said you cannot create your own tool for data collection. A web scraper can be built entirely from scratch, such as Python proxy scrapers or Squidweb, or be run as a script, but it does require advanced programming knowledge. For example, many programmers use cURL. It stands for ‘Client URL’, a command-line tool used for transferring data via network protocols.
cURL makes use of URL syntax to transfer data to and from servers. It’s a really popular and important way of collecting data, mainly thanks to its versatility. cURL was created for complex operations and is available for almost every platform. On top of that, chances are your system already has cURL installed by default.
Because of its versatility, cURL can be used for a variety of use cases, such as proxy support, FTP uploads, SSL connections, and, most important for our topic, downloading and uploading entire websites using one of the supported protocols.
In short, the more functions you want to introduce to your software, the more complicated the design process will get.
What you should be aware of when doing Web scraping?
- The UI can be your greatest ally or your greatest foe
The user interface between web scrapers usually differs significantly. Some web scrapers have a minimal UI and run with a command line. For many, this is really counterintuitive and difficult to use.
Other web scrapers offer a more polished UX. They incorporate a full-fledged UI where the website is fully rendered for the user to just click on the data they want to scrape. These web scrapers are usually easier to work with and are really beginner-friendly. On top of that, some programs will even display tips and suggestions to make sure the user understands each and every component of that web scraping tool.
- Be mindful about the workspace of your web scraper – Cloud vs Local
Local web scrapers will run on your computer using its resources and Internet connection. The process is heavy on your computer’s CPU and RAM, meaning scraping vast amounts of data for many hours will take its toll on your system.
Furthermore, if your scraper is set to run on a large number of URLs (such as product pages) and depending on the services your ISP offers, you risk suffering additional traffic costs.
Cloud-based web scrapers run on an off-site server which is usually provided by the company that developed the scraper itself. This option is resource-friendly and does not throw a heavy workload on your computer’s resources. In addition, this is compatible with additional advanced features, such as IP rotation, which can prevent your scraper from getting blocked from major websites due to their scraping activity.
What is Web crawling?
Web crawling is the process of indexing data on web pages by using a program or automated script. These scripts or programs are usually called web crawlers, spiders or simply crawlers. They crawl one page at a time through a website until all pages have been indexed. Web crawlers help in collecting information about a website and the links related to them, and also help in validating the HTML code and hyperlinks.
Data crawling targets the URL of the website, the meta tag information, the Web page content, the links in the webpage and the destinations leading from those links, the web page title and any other relevant information.
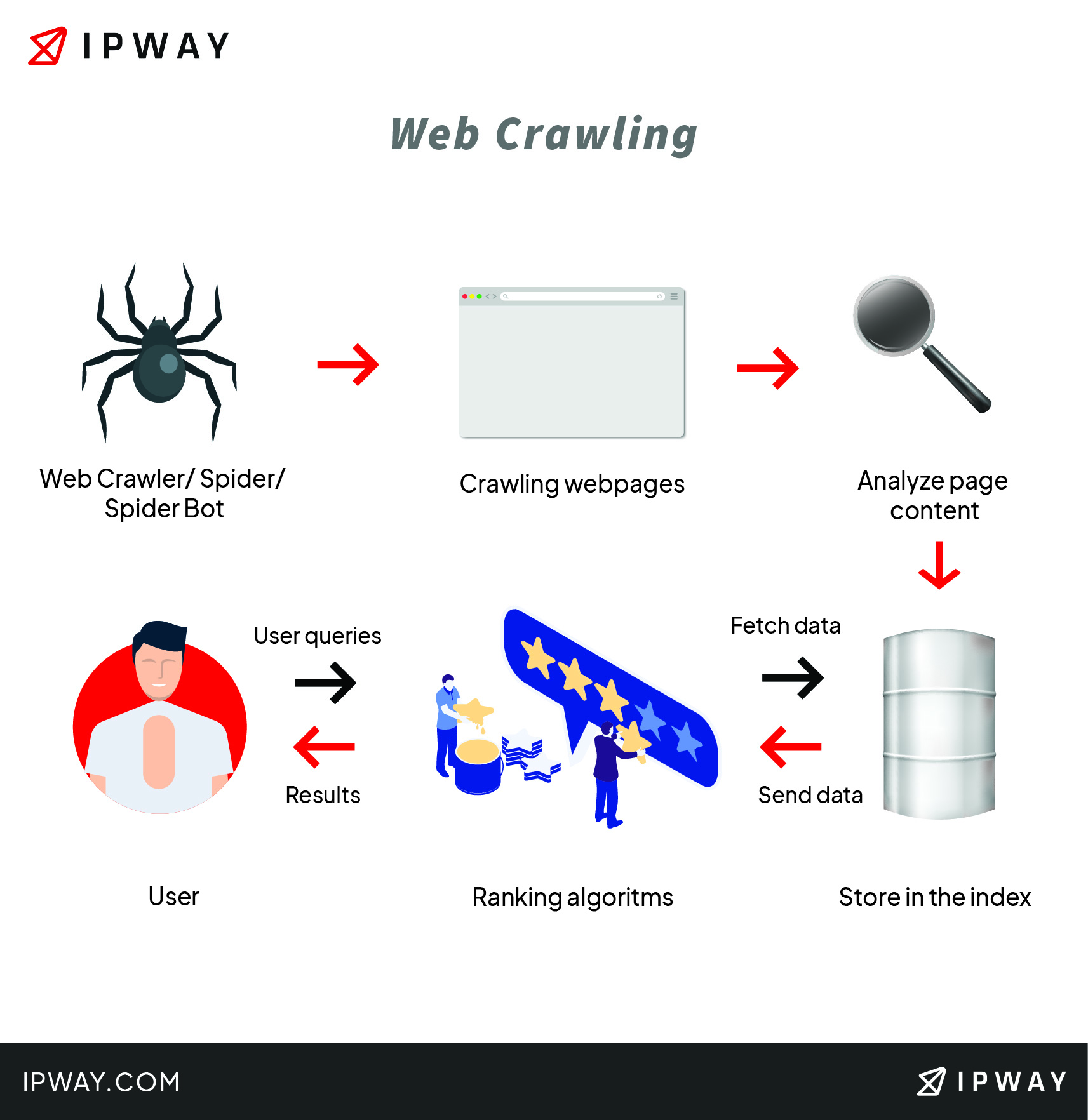
The most common example is the search engines themselves, like Google with its Googlebot crawler and even WebCrawler, one of the oldest surviving search engines on the web today.
They crawl the web so they can index pages and display them in the search results. Or, for a more specific example, these crawlers help you identify all the page URLs of a specific website if you don’t know them already or if you are looking for URLs containing a specific word.
What is Web crawling used for?
Web crawling itself is important for sending queries against the index and also providing the Web pages that match the queries. In addition, crawlers help the process of Web archiving, which involves large sets of webpages to be periodically collected and archived.
Web crawlers are also used in data mining, since pages are analysed for different properties like statistics, and data analytics are then performed on them.
What’s the difference between Web scraping and Web crawling?
Usually, it is believed that Web scraping and Web crawling are one and the same. But they are quite different. While scraping is about extracting the data from one or more websites to gain relevant and detailed insight, crawling is about finding or discovering URLs or links on the web.
Generally speaking, Web crawling is a less difficult task than Web scraping, simply because you (more or less) just pull a bunch of URLs from the Web and that’s it. When it comes to Web scraping, you might end up with a lot more data fields. You can extract a single URL, but you scrape and collect information for other data fields that are displayed on the website.
But it is important to note that, although different in purpose, scrapers and crawlers go hand in hand when it comes to gathering vast amounts of data. It’s about different purposes and different outputs, but they complement each other.
Why do you need to use both of them?
When you extract data from the Internet, you usually combine Web scraping and Web crawling. First, you crawl – you search and discover the URLs. Then you download the HTML files and then you scrape data from them. In the end, you extract data and export it into a format of your choice to be stored and used.
The more you crawl, the more you scrape, because once web crawlers start crawling a page, they discover new pages via links. Those pages can be then further crawled, thus adding more volume of data that needs to be scraped and exported. It is a complex and interesting process on which many companies base their business strategy on.
However, due to complex and often confusing policies and regulations, these practices will eventually encounter some obstacles.
What are the challenges you need to overcome when collecting data?
There are some things that need to be taken into consideration when collecting data across the Web. This is why sometimes you might encounter one or more obstacles, so let’s list the most common ones.
While web scraping is not an illegal practice, policies vary among sites. Some sites have strict, anti-scraping policies, mainly due to their competitive nature. In addition, web scraping is really heavy on server resources, thus affecting the site’s performance.
So, the first challenge companies need to overcome is making sure the websites they are about to scrape can, in fact, be scraped successfully and legally. As web scraping is such an insightful tool and with the immense effect it has on businesses, it should be done efficiently and responsibly.
Captchas are another difficult obstacle to surmount. Due to the automatic nature of the scraping process, captchas have become quite efficient at blocking scrapers. Captchas help differentiate between humans and bots, so beware of such implementations.
You should know companies can offer anti-bot and anti-scraping services for websites. Some web application firewalls also have some anti-bot capabilities, although limited. In most cases, this is not usually a significant challenge when web scraping.
IP blacklisting is another risk that needs to be carefully dealt with. Some websites can block IP addresses either manually or based on criteria such as geolocation and DNSRBL(Domain Name System Blacklist). In this case, you could resort to rotating IPs, but you cannot know their reputation and efficiency beforehand. So you risk getting your hands on a rotation of IPs that are already blocked. In addition, you would commit to getting taxed by traffic, and the respective costs are often difficult to predict.
A more viable and cost efficient solution would be to make sure you are using dedicated IP addresses. They are geolocated and can be pre-tested to check if they meet your requirements. Dedicated IPv4 and IPv6 addresses can ensure you will not get blocked from the websites you want to scrape and managing them is completely up to you.
Websites can declare if crawling is allowed or not in the robots.txt file and allow partial access, limit the crawl rate, specify the optimal time to crawl, and more. This file is the most important part of the web scraping process. It specifies the policies and regulations of that specific website and indicates whether data collection is allowed or not, in order to avoid overloading the site with requests.
Honeypot traps are another common challenge that needs to be properly addressed. There are pages inside some websites that a human will never click on but a web scraper bot that is accessing every possible link might. These are specifically designed for web scrapers and once the honey pot links are clicked, it’s highly likely that you will get banned from that site.
Conclusion
Data collection is a formidable advantage for numerous companies and businesses. If done correctly and responsibly, the outcome will be extremely fruitful. Companies need to make sure they are allowed to legally scrape the desired websites and be considerate of the website and server resources they are targeting.
Web crawling and web scraping are quite different in their nature, but they serve almost the same purpose and often, if not always, go hand in hand. It is important to know which method of web scraping is best for your scenario and make sure the choice is relevant to your technical skills. Having mastered that, your business will thrive and you will successfully adapt your strategy to outmatch the competition.